Hystrix
1 概念:
概述
在分布式系统下-微服务之间不可避免地会发生相互调用-但每个系统都无法百分之百保证自身运行不出问题。在服务调用中-很可能面临依赖服务失效的问题(网络延时-服务异常-负载过大无法及时响应)。因此需要一个组件-能提供强大的容错能力-为服务间调用提供保护和控制。
我们的目的:_当我自身 依赖的服务不可用时-服务自身不会被拖垮。防止微服务级联异常_。
图。
本质:就是隔离坏的服务-不让坏服务拖垮其他服务(调用坏服务的服务)。
比如:武汉发生疫情-隔离它-不让依赖于武汉的地方感染。
和我们课程中熔断降级更贴切一点:北京从武汉招聘大学生-武汉有疫情了-当北京去武汉请求大学生来的时候-武汉熔断-然后北京启动自身的备用逻辑:去上海找大学生(降级)。
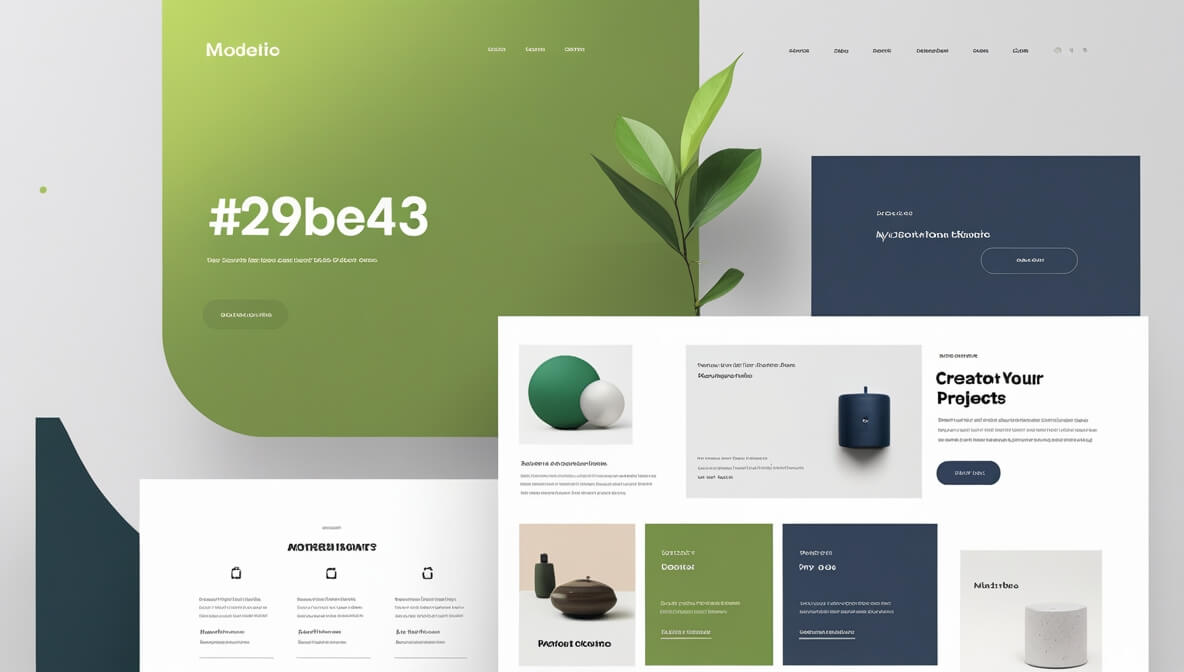
舱壁模式
舱壁模式(Bulkhead)隔离了每个工作负载或服务的关键资源-如连接池、内存和CPU-硬盘。每个工作单元都有独立的 连接池-内存-CPU。
使用舱壁避免了单个服务消耗掉所有资源-从而导致其他服务出现故障的场景。 这种模式主要是通过防止由一个服务引起的级联故障来增加系统的弹性。
据说泰坦尼克原因:泰坦尼克号上有16个防水舱-设计可以保障如果只有4个舱进水-密闭和隔离可以阻止水继续进入下一个防水舱-从而保证船的基本浮力。
但是当时冰山从侧面划破了船体-从而导致有5个防水舱同时进水-而为了建造豪华的头等舱大厅-也就是电影里杰克和罗斯约会的地方-5号舱的顶部并未达到密闭所需要的高度-水就一层层进入了船体-隔离的失败导致了泰坦尼克的沉没。
> 舱壁模式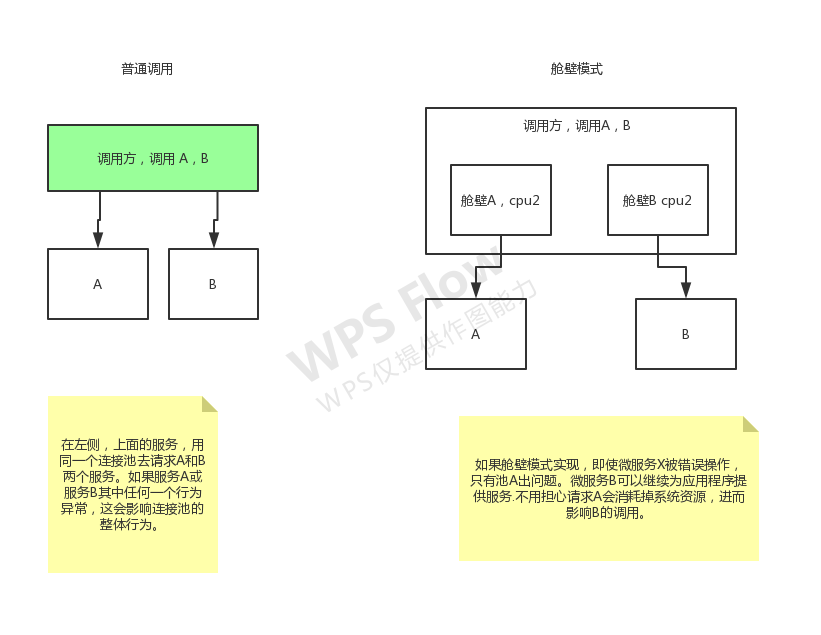
给我们的思路:可以对每个请求设置-单独的连接池-配置连接数-不要影响 别的请求。就像一个一个的防水舱。
对在公司中的管理也一样:给每个独立的 小组-分配独立的资源-比如产品-开发-测试。在小公司-大多数情况 这些资源都是共享的-有一个好处是充分利用资源-坏处是-如果一个项目延期-会影响别的项目推进。自己权衡利弊。
最近比较火的一句话: 真正的知识-是 产品提高一个等级和成本提高0.2元的 痛苦抉择。
雪崩效应
每个服务 发出一个HTTP请求都会 在 服务中 开启一个新线程。而下游服务挂了或者网络不可达-通常线程会阻塞住-直到Timeout。如果并发量多一点-这些阻塞的线程就会占用大量的资源-很有可能把自己本身这个微服务所在的机器资源耗尽-导致自己也挂掉。
如果服务提供者响应非常缓慢-那么服务消费者调用此提供者就会一直等待-直到提供者响应或超时。在高并发场景下-此种情况-如果不做任何处理-就会导致服务消费者的资源耗竭甚至整个系统的崩溃。一层一层的崩溃-导致所有的系统崩溃。
> 《雪崩示意图》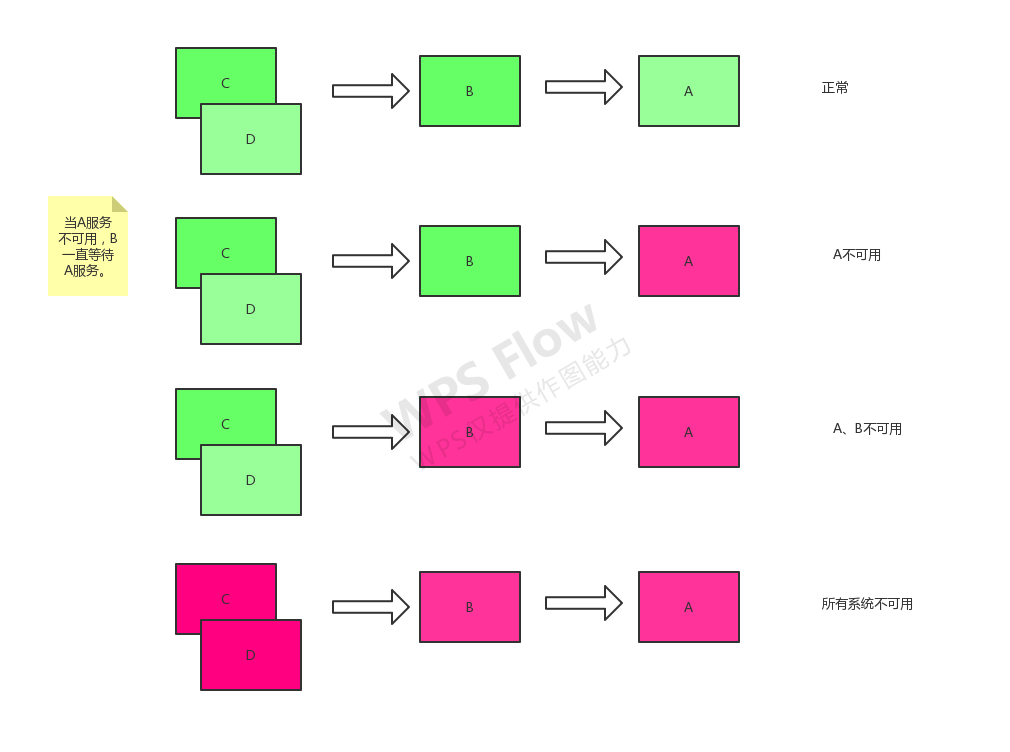
雪崩:由基础服务故障导致级联故障的现象。描述的是:提供者不可用 导致消费者不可用-并将不可用逐渐放大的过程。像滚雪球一样-不可用的服务越来越多。影响越来越恶劣。
雪崩三个流程:
服务提供者不可用
重试会导致网络流量加大-更影响服务提供者。
导致服务调用者不可用-由于服务调用者 一直等待返回-一直占用系统资源。
(不可用的范围 被逐步放大)
服务不可用原因:
服务器宕机
网络故障
宕机
程序异常
负载过大-导致服务提供者响应慢
缓存击穿导致服务超负荷运行
总之 : 基础服务故障 导致 级联故障 就是 雪崩。
容错机制
必须为网络请求设置超时。一般的调用一般在几十毫秒内响应。如果服务不可用-或者网络有问题-那么响应时间会变很长。长到几十秒。
每一次调用-对应一个线程或进程-如果响应时间长-那么线程就长时间得不到释放-而线程对应着系统资源-包括CPU,内存-得不到释放的线程越多-资源被消耗的越多-最终导致系统崩溃。
因此必须设置超时时间-让资源尽快释放。
想一下家里的保险丝-跳闸。如果家里有短路或者大功率电器使用-超过电路负载时-就会跳闸-如果不跳闸-电路烧毁-波及到其他家庭-导致其他家庭也不可用。通过跳闸保护电路安全-当短路问题-或者大功率问题被解决-在合闸。
自己家里电路-不影响整个小区每家每户的电路。
断路器
``
如果对某个微服务请求有大量超时(说明该服务不可用)-再让新的请求访问该服务就没有意义-只会无谓的消耗资源。例如设置了超时时间1s-如果短时间内有大量的请求无法在1s内响应-就没有必要去请求依赖的服务了。
`
这样就实现了微服务的“自我修复”:当依赖的服务不可用时-打开断路器-让服务快速失败-从而防止雪崩。当依赖的服务恢复正常时-又恢复请求。
> 断路器开关时序图
`sh
第一次正常第二次提供者异常提供者多次异常后-断路器打开后续请求-则直接降级-走备用逻辑。
`
断路器状态转换的逻辑:
`plain
关闭状态:正常情况下-断路器关闭-可以正常请求依赖的服务。打开状态:当一段时间内-请求失败率达到一定阈值-断路器就会打开。服务请求不会去请求依赖的服务。调用方直接返回。不发生真正的调用。重置时间过后-进入半开模式。半开状态:断路器打开一段时间后-会自动进入“半开模式”-此时-断路器允许一个服务请求访问依赖的服务。如果此请求成功(或者成功达到一定比例)-则关闭断路器-恢复正常访问。否则-则继续保持打开状态。断路器的打开-能保证服务调用者在调用异常服务时-快速返回结果-避免大量的同步等待-减少服务调用者的资源消耗。并且断路器能在打开一段时间后继续侦测请求执行结果-判断断路器是否能关闭-恢复服务的正常调用。
`
> 《熔断.doc》《断路器开关时序图》《状态转换》
降级
为了在整体资源不够的时候-适当放弃部分服务-将主要的资源投放到核心服务中-待渡过难关之后-再重启已关闭的服务-保证了系统核心服务的稳定。当服务停掉后-自动进入fallback替换主方法。
用fallback方法代替主方法执行并返回结果-对失败的服务进行降级。当调用服务失败次数在一段时间内超过了断路器的阈值时-断路器将打开-不再进行真正的调用-而是快速失败-直接执行fallback逻辑。服务降级保护了服务调用者的逻辑。
`sh
熔断和降级:共同点: 1、为了防止系统崩溃-保证主要功能的可用性和可靠性。 2、用户体验到某些功能不能用。不同点: 1、熔断由下级故障触发-主动惹祸。 2、降级由调用方从负荷角度触发-无辜被抛弃。
`
19年春晚 百度 红包-凤巢的5万台机器熄火4小时-让给了红包。
Hystrix
spring cloud 用的是 hystrix-是一个容错组件。
Hystrix实现了 超时机制和断路器模式。
Hystrix是Netflix开源的一个类库-用于隔离远程系统、服务或者第三方库-防止级联失败-从而提升系统的可用性与容错性。主要有以下几点功能:
2 Hystrix 使用
hystrix独立使用脱离spring cloud
代码:study-hystrix项目-HelloWorldHystrixCommand类。看着类讲解。
关注点:
继承hystrixCommand
重写run
fallback(程序发生非HystrixBadRequestException异常-运行超时-熔断开关打开-线程池/信号量满了)
熔断(熔断机制相当于电路的跳闸功能-我们可以配置熔断策略为当请求错误比例在10s内>50%时-该服务将进入熔断状态-后续请求都会进入fallback。)
结果缓存(支持将一个请求结果缓存起来-下一个具有相同key的请求将直接从缓存中取出结果-减少请求开销。)
这个例子-只是独立使用hystrix- 通过这个例子-了解 hystrix