Redis的前世今生
基本介绍
#### 数据存储演变过程
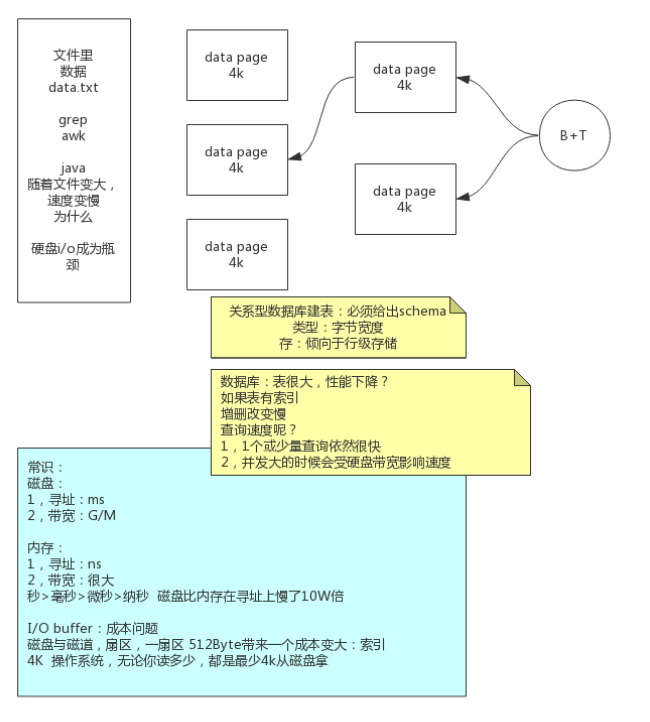
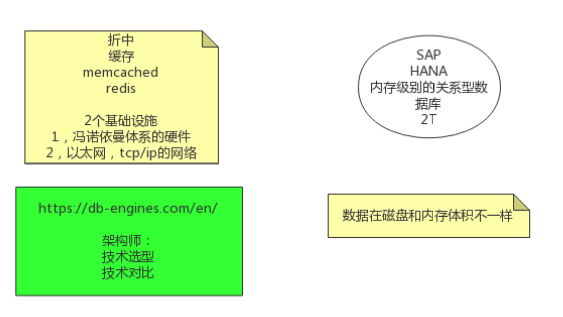
数据的存储方式受限于:
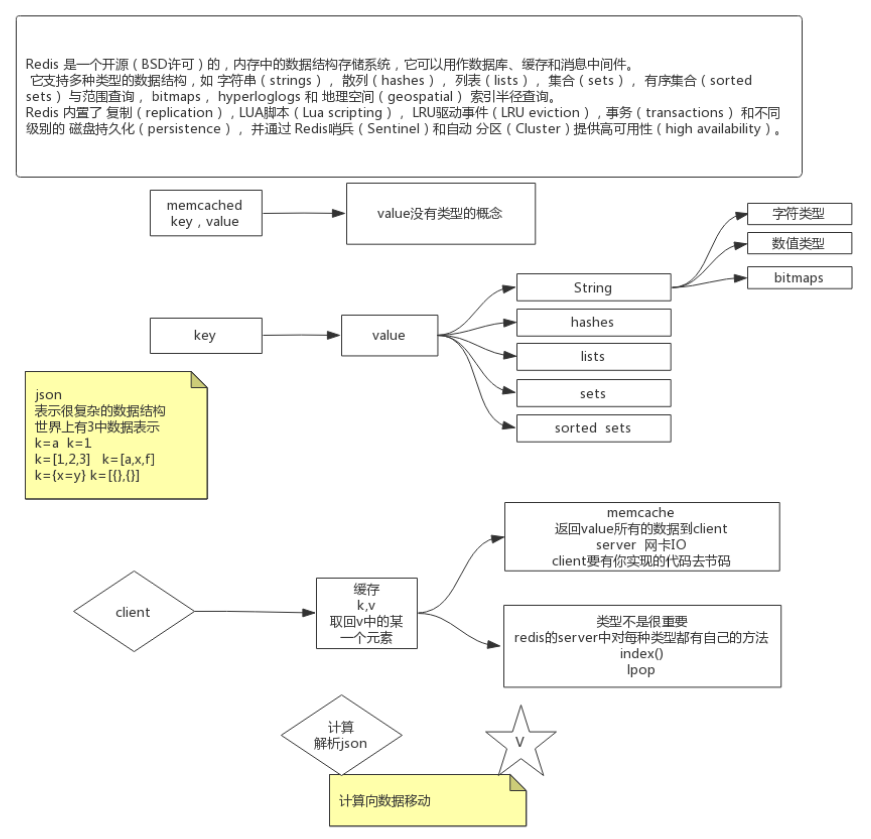
Redis的特点-对比Memcache , value有类型 , 有类型对应的方法(API) , 计算向数据移动
#### 安装

``plain
centos 6.xredis官网5.xhttp://download.redis. io/releases/redis-5.0.5.tar.gz1 , yum install wget2,cd ~3,mkdir soft4,cd soft5,wget http://download.redis.io/releases/redis-5.0.5.tar.gz6,tar xf redis.. tar.gz7,cd redis-src8,看README md9, make.. install gcc..... make distclean10,make11,cdsrc .. .生成了可执行程序12, cd ..13,make install PREFIX=/opt/mashibing/redis514,vi /etc/profileexport REDIS_ _HOME= /opt/mashibing/redis5export PATH= $PATH:$REDIS_ _HOME/bin.source /etc/profile15,cd utils16,./install_ server.sh ( 可以执行- -次或多次))一个物理机中可以有多个redis实例(进程) ,通过port区分b)可执行程序就-份在目录,但是内存中未来的多个实例需要各自的配置文件,持久化目录等资源 c) service redis_ 6379 start/stop/stauts > linux /etc/init.d/***d)脚本还会帮你启动!17.ps -fe| grep redis
`
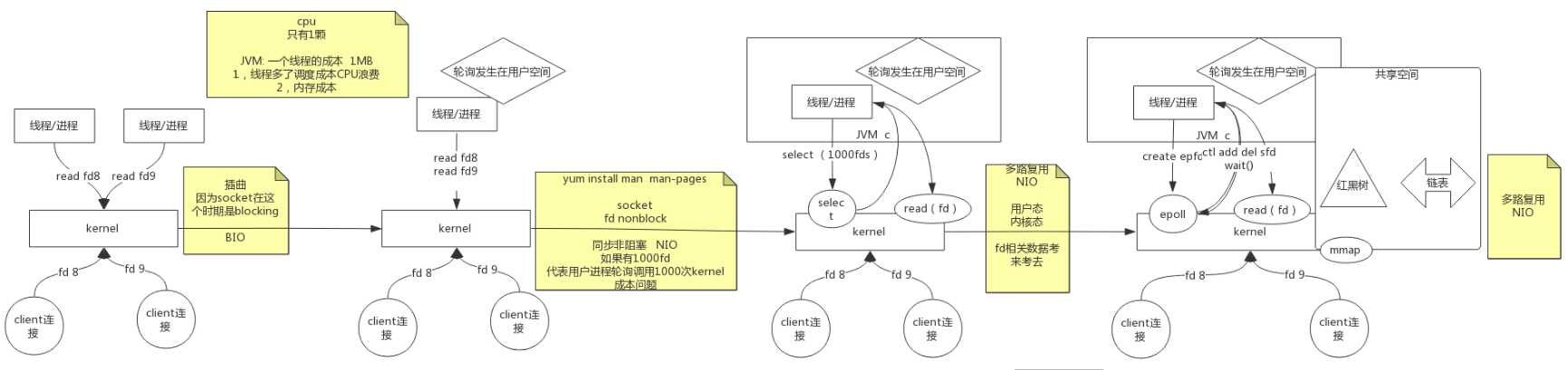
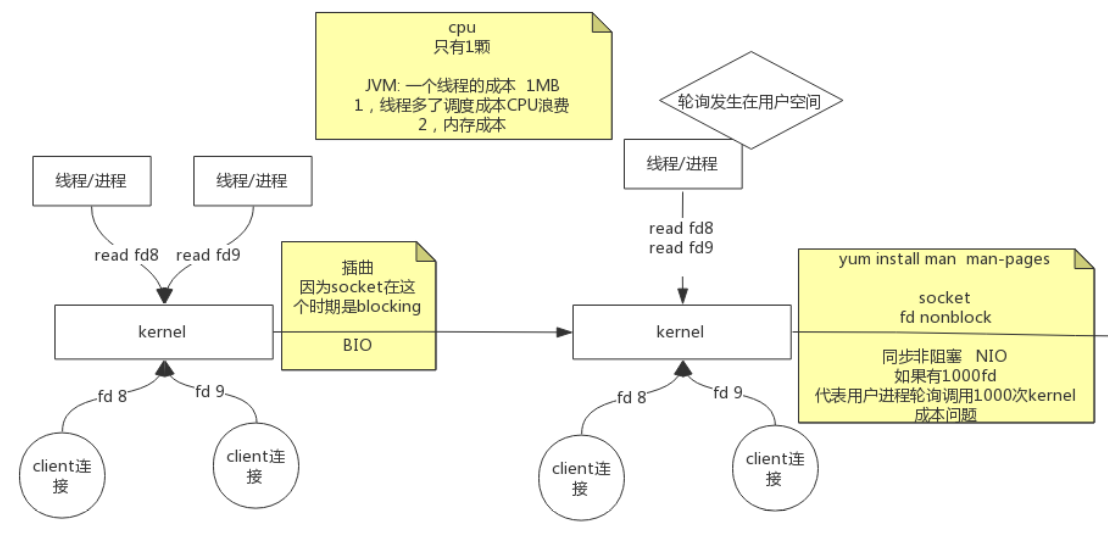
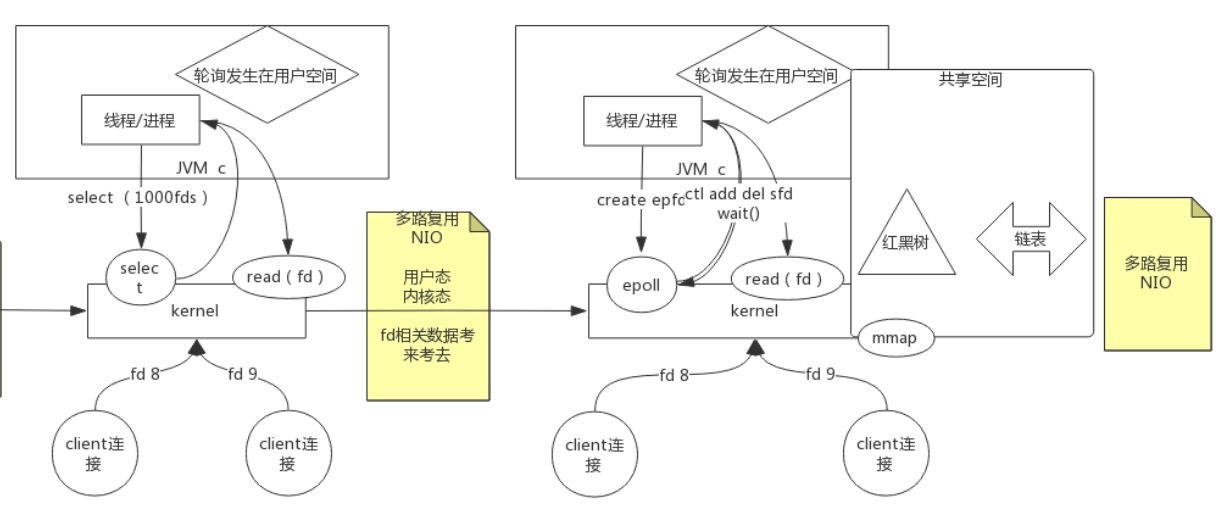
#### BIO->同步非阻塞NIO->多路复用NIO
内核不断变化
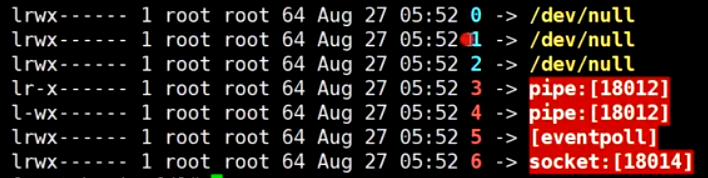
Redis进程的文件描述符 0: 标准输入 1: 标准输出 2: 报错输出 3,4: pipe调用 5: epoll
kafka: sendfile + mmap 零拷贝: sendfile系统调用
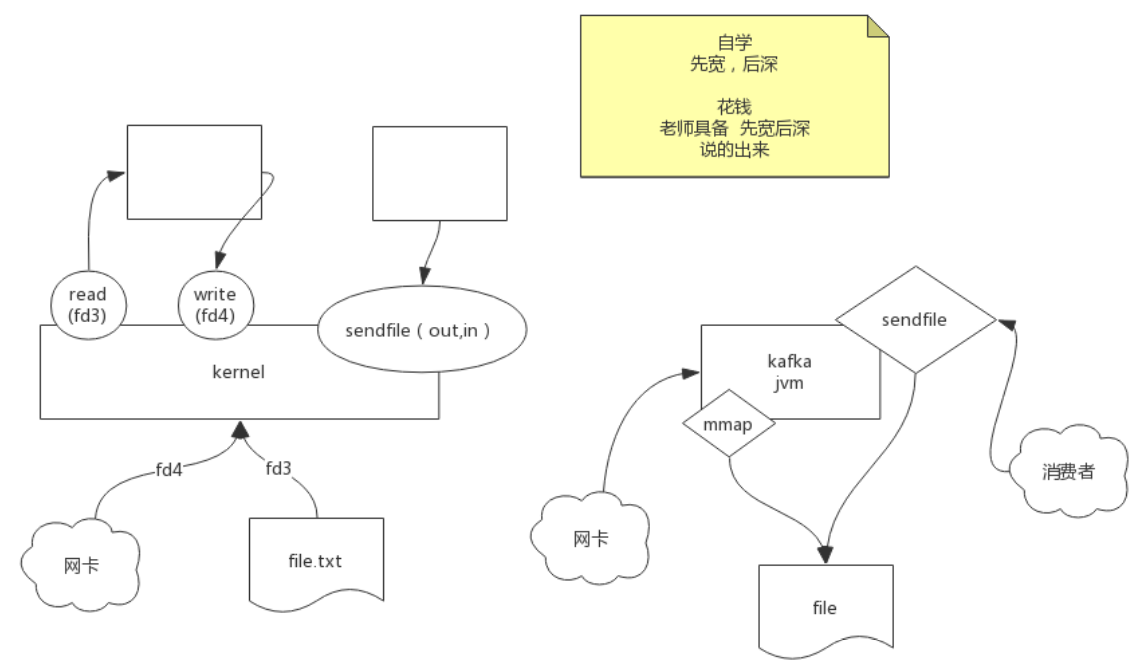
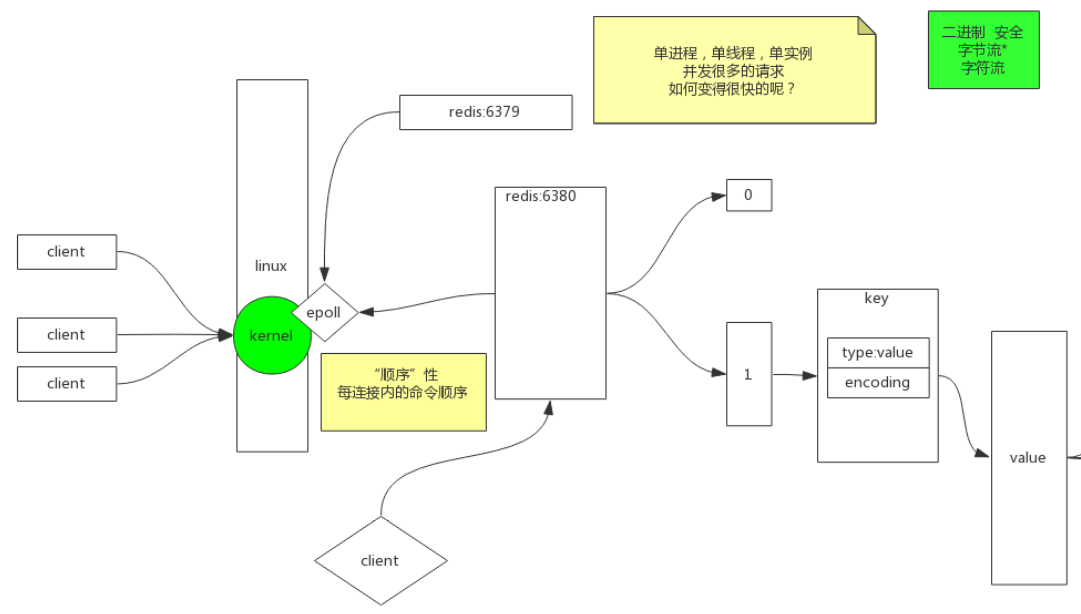
Redis为什么快: epoll : epoll是 Linux内核 为处理大批量 文件描述符 而作了改进的poll-是Linux下多路复用IO接口select/poll的增强版本-它能显著提高程序在大量 并发连接 中只有少量活跃的情况下的系统 CPU利用率。另一点原因就是获取事件的时候-它无须遍历整个被侦听的描述符集-只要遍历那些被内核IO事件异步唤醒而加入Ready队列的描述符集合就行了。
顺序性: 每个连接内的命令顺序 内存寻址是ns级, 网卡是ms级, 10万倍差距, 10万连接同时时到达, 可能会产生秒级响应 mysql开启缓存, 想模仿redis, 性能反而会低, 多了一次判断过程, 增加了内存空间占用
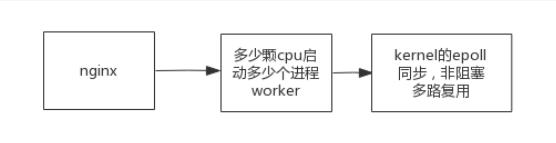
#### 类比Nginx
5种数据类型
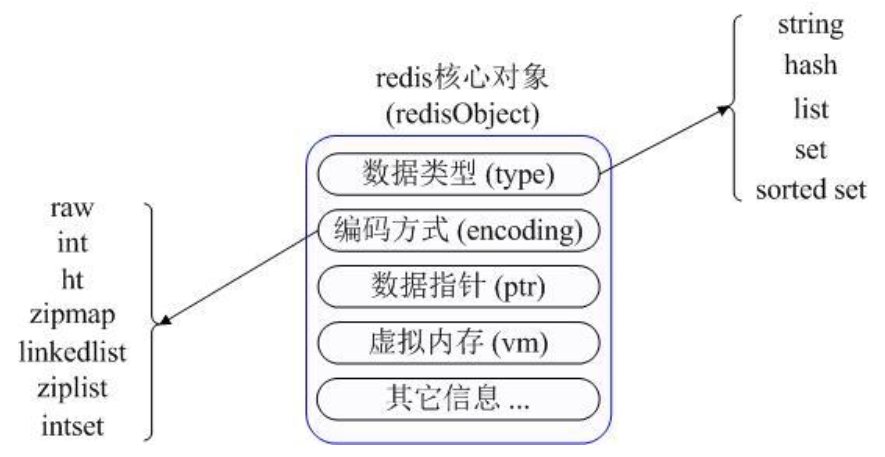
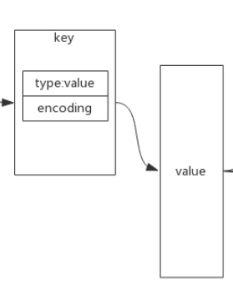
可以根据用户的指令, 看是不是和key里存的type匹配, 不匹配直接返回, 规避异常
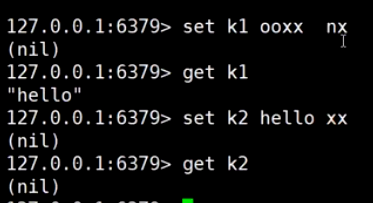
nx: 只能新建 分布式锁 xx: 只能更新
#### String
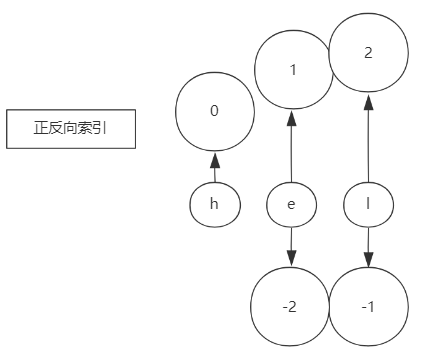
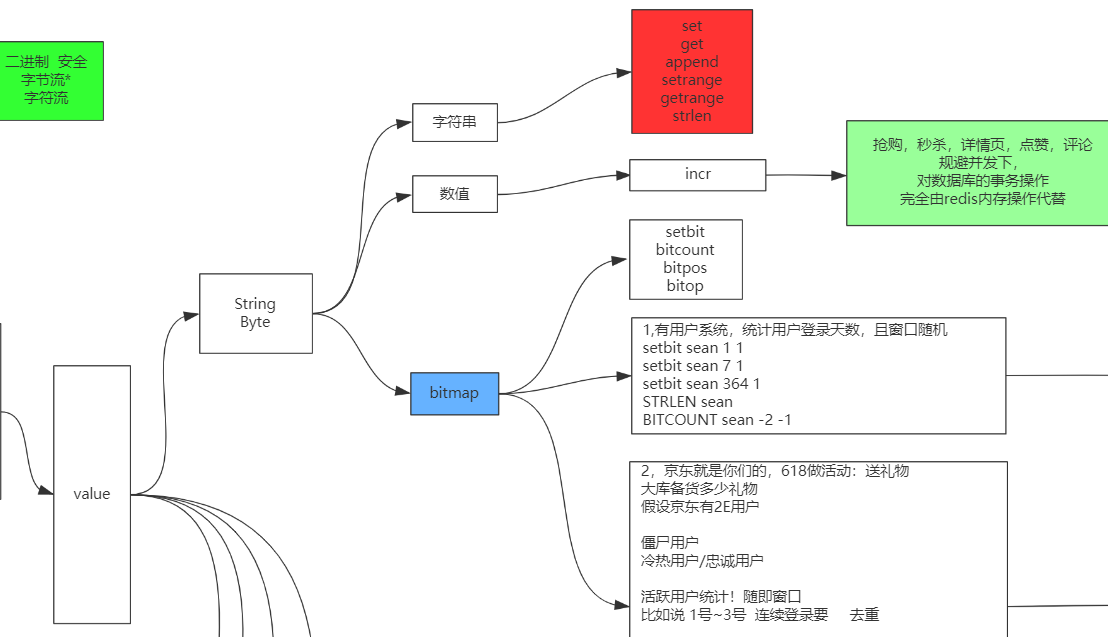
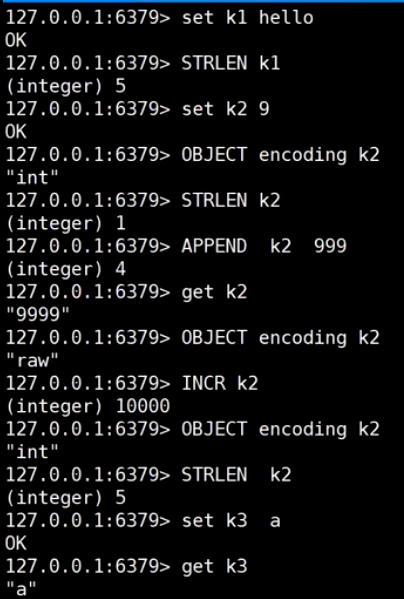
二进制安全: Redis只取字节流, 一个字符一个字节
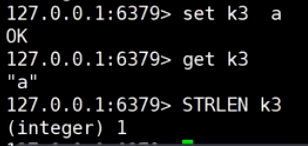

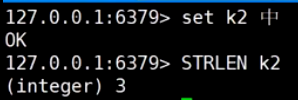
和Xshell设置有关
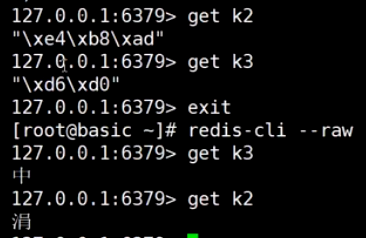
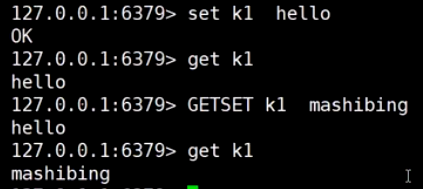
GETSET减少一次I/O
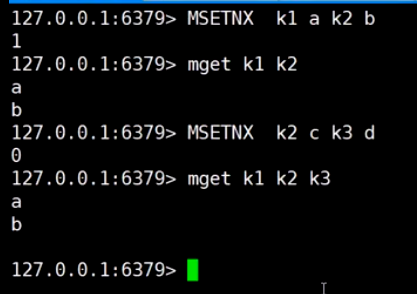
MSETNX原子性set, k2已经存在, 集体失败
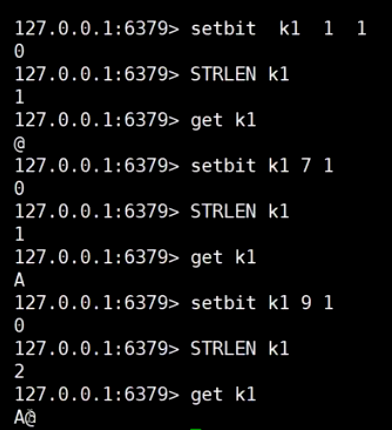
##### bitmap (活跃度|登录数)
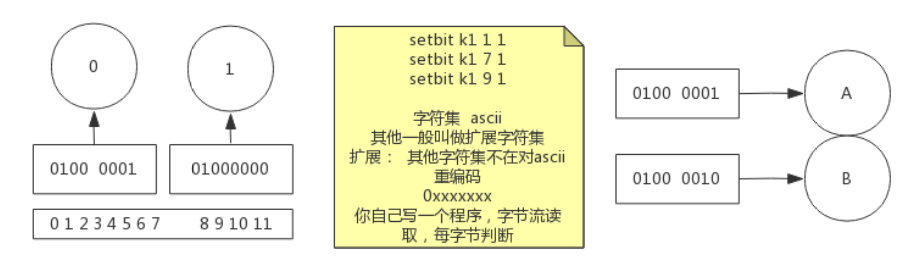
按位与