
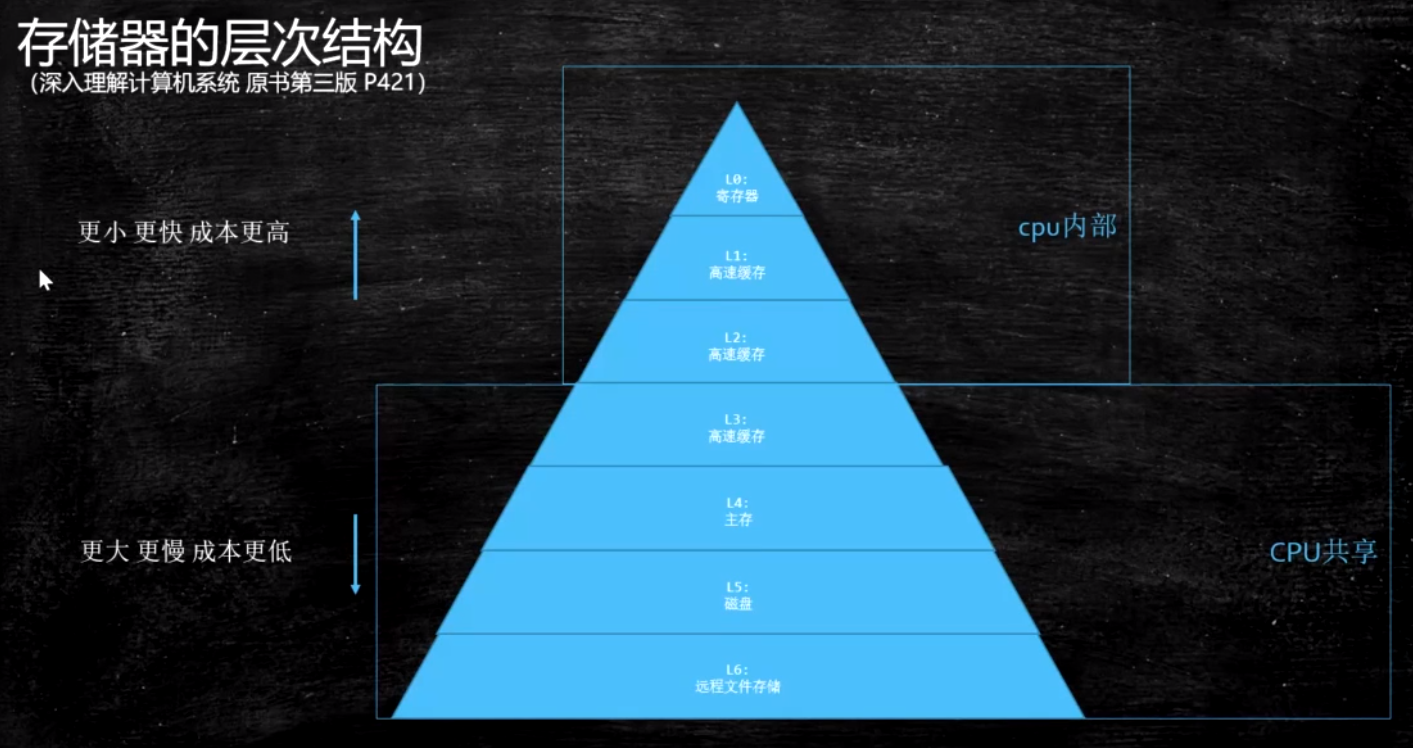
离CPU越近, 速度越快, 空间越小

数据不一致问题


缓存锁
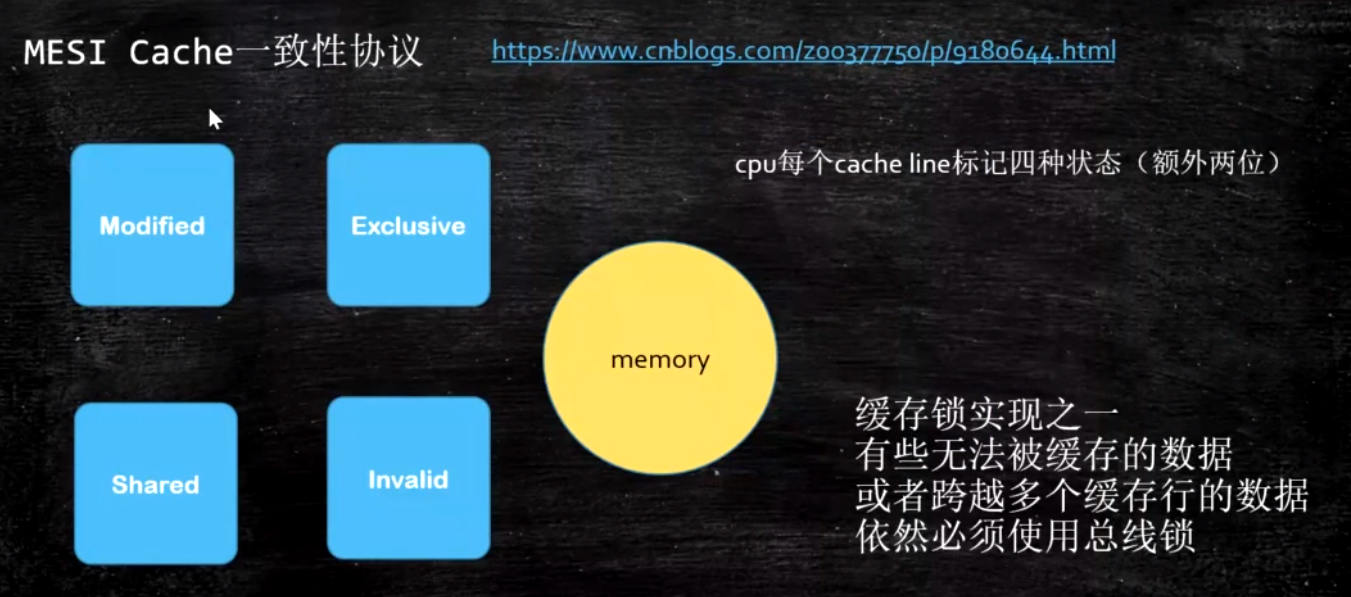
和主存内容比较 Modified改过, 再加载 Exclusive独享 Shared我读的时候别人也在读 Invalid读时被别的CPU改过
现代CPU的数据一致性实现 = 缓存锁(MESI …) + 总线锁读取缓存以cache line为基本单位-目前64bytes
位于同一缓存行的两个不同数据-被两个不同CPU锁定-产生互相影响的伪共享问题
伪共享问题:JUC/c_028_FalseSharing
使用缓存行的对齐能够提高效率

乱序问题
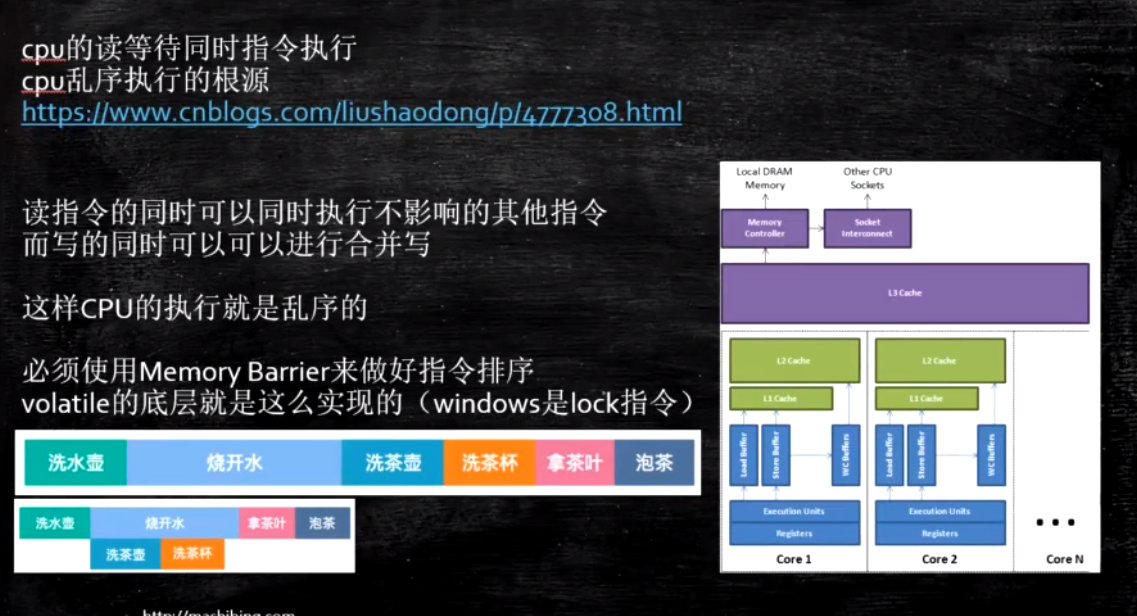
CPU为了提高指令执行效率-会在一条指令执行过程中(比如去内存读数据(慢100倍))-去同时执行另一条指令-前提是-两条指令没有依赖关系
写操作也可以进行合并
乱序执行的证明:JVM/jmm/Disorder.java
如何保证特定情况下不乱序
硬件内存屏障 X86
> sfence: store| 在sfence指令前的写操作当必须在sfence指令后的写操作前完成。 > lfence:load | 在lfence指令前的读操作当必须在lfence指令后的读操作前完成。 > mfence:modify/mix | 在mfence指令前的读写操作当必须在mfence指令后的读写操作前完成。
> 原子指令-如x86上的”lock …” 指令是一个Full Barrier-执行时会锁住内存子系统来确保执行顺序-甚至跨多个CPU。Software Locks通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序
JVM级别如何规范(JSR133)
> LoadLoad屏障:
> 对于这样的语句Load1; LoadLoad; Load2-
>
> ``
> 在Load2及后续读取操作要读取的数据被访问前-保证Load1要读取的数据被读取完毕。
> `
>
> StoreStore屏障:
>
> `
> 对于这样的语句Store1; StoreStore; Store2-
>
> 在Store2及后续写入操作执行前-保证Store1的写入操作对其它处理器可见。
> `
>
> LoadStore屏障:
>
> `
> 对于这样的语句Load1; LoadStore; Store2-
>
> 在Store2及后续写入操作被刷出前-保证Load1要读取的数据被读取完毕。
> `
>
> StoreLoad屏障:
> 对于这样的语句Store1; StoreLoad; Load2-
>
> 在Load2及后续所有读取操作执行前-保证Store1的写入对所有处理器可见。
volatile的实现细节
> StoreStoreBarrier > > volatile 写操作 > > StoreLoadBarrier
> LoadLoadBarrier > > volatile 读操作 > > LoadStoreBarrier

synchronized实现细节


观察虚拟机配置
java -XX:+PrintCommandLineFlags -version
普通对象

数组对象




Heap
Method Area
Runtime Constant Pool
Native Method Stack
Direct Memory
> JVM可以直接访问的内核空间的内存 (OS 管理的内存) > > NIO - 提高效率-实现zero copy
思考:
> 如何证明1.7字符串常量位于Perm-而1.8位于Heap? > > 提示:结合GC- 一直创建字符串常量-观察堆-和Metaspace
PC 程序计数器
> 存放指令位置 > > 虚拟机的运行-类似于这样的循环: > > while( not end ) { > > 取PC中的位置-找到对应位置的指令; > > 执行该指令; > > PC ++; > > }


