分布式事务
事务(Transaction),一般是指要做的或所做的事情,由事务开始(begin transaction)和事务结束(end transaction)之间执行的全体操作组成。
简单的讲就是,要么全部被执行,要么就全部失败。
那分布式事务,自然就是运行在分布式系统中的事务,是由多个不同的机器上的事务组合而成的。同上,只有分布式系统中所有事务执行了才能是成功,否则失败。
事务的基本特征ACID:
- 原子性(Atomicity)
- 一个事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。
- 一致性
- 指事务执行前和执行后,数据是完整的。
- 隔离性
- 一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
- 持久性
- 也称为永久性,一个事务一旦提交,它对数据库中数据的改变就应该是永久性的保存下来了。
分布式事务的目标:解决多个独立事务一致性的问题。
我们遇到的问题:
分布式事务:一个功能,横跨多个微服务,由于每个微服务不在一个库,没法用数据库事务来保证事务。
网约车例子:乘客支付订单。支付系统中,支付表更新,订单系统,订单库 订单状态更新为已支付。
订单,支付表,在不同的库,如何保证两个库之间的事务。
支付操作:支付修改余额,修改订单状态。
分布式事务解决方案
二阶段提交协议
基于XA协议的,采取强一致性,遵从ACID.
2PC:(2阶段提交协议),是基于XA/JTA规范。
XA
XA是由X/Open组织提出的分布式事务的架构(或者叫协议)。XA架构主要定义了(全局)事务管理器(Transaction Manager)和(局部)资源管理器(Resource Manager)之间的接口。XA接口是双向的系统接口,在事务管理器(Transaction Manager)以及一个或多个资源管理器(Resource Manager)之间形成通信桥梁。也就是说,在基于XA的一个事务中,我们可以针对多个资源进行事务管理,例如一个系统访问多个数据库,或即访问数据库、又访问像消息中间件这样的资源。这样我们就能够实现在多个数据库和消息中间件直接实现全部提交、或全部取消的事务。XA规范不是java的规范,而是一种通用的规范。
JTA
JTA(Java Transaction API),是J2EE的编程接口规范,它是XA协议的JAVA实现。它主要定义了:
一个事务管理器的接口javax.transaction.TransactionManager,定义了有关事务的开始、提交、撤回等操作。
一个满足XA规范的资源定义接口javax.transaction.xa.XAResource,一种资源如果要支持JTA事务,就需要让它的资源实现该XAResource接口,并实现该接口定义的两阶段提交相关的接口。
《二阶段提交协议》
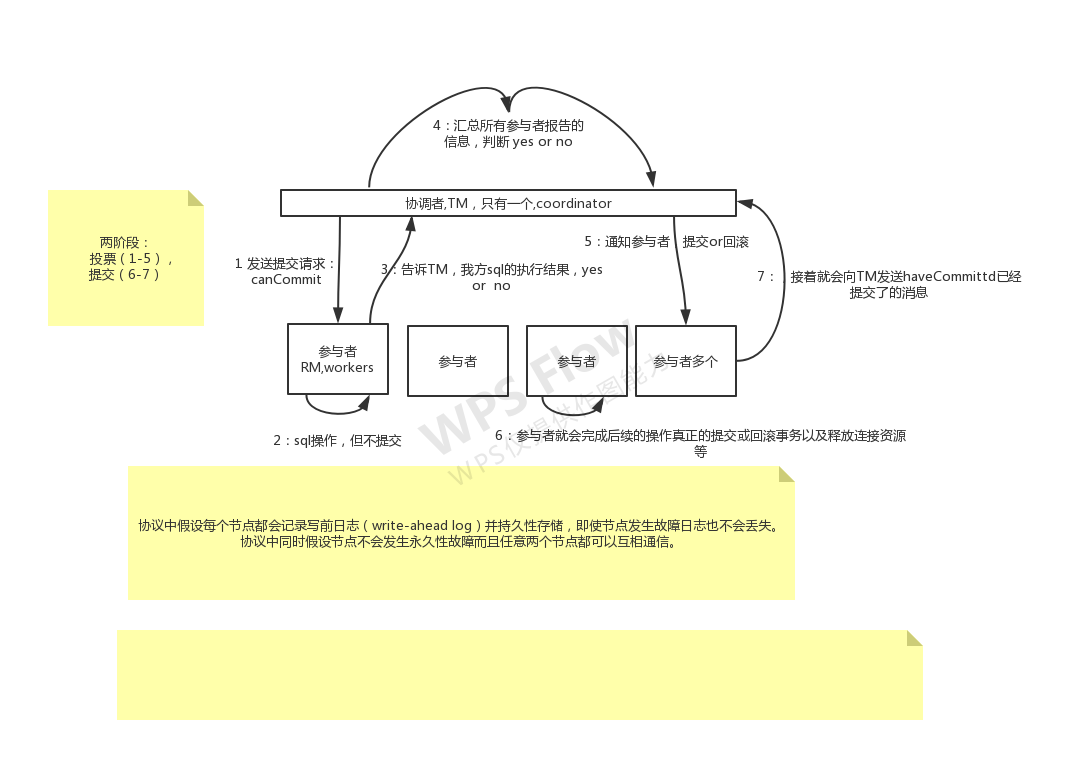
过程
1 | 1.请求阶段(commit-request phase,或称表决阶段,voting phase) |
缺点:
- 单点故障:事务的发起、提交还是取消,均是由老大协调者管理的,只要协调者宕机,那就凉凉了。
- 同步阻塞缺点:从上面介绍以及例子可看出,我们的参与系统中在没收到老大的真正提交还是取消事务指令的时候,就是锁定当前的资源,并不真正的做些事务相关操作,所以,整个分布式系统环境就是阻塞的。
- 数据不一致缺点:就是说在老大协调者向小弟们发送真正提交事务的时候,部分网路故障,造成部分系统没收到真正的指令,那么就会出现部分提交部分没提交,因此,这就会导致数据的不一致。
无法解决的问题
当协调者出错,同时参与者也出错时,两阶段无法保证事务执行的完整性。
考虑协调者再发出commit消息之后宕机,而唯一接收到这条消息的参与者同时也宕机了。
那么即使有了新的协调者,这条事务的状态也是不确定的,没人知道事务是否被已经提交。知道的人已经被灭口了。
三阶段提交协议
采取强一致性,遵从ACID。
在二阶段上增加了:超时和预提交机制。
有这三个主阶段,canCommit、preCommit、doCommit这三个阶段
《三阶段提交协议》
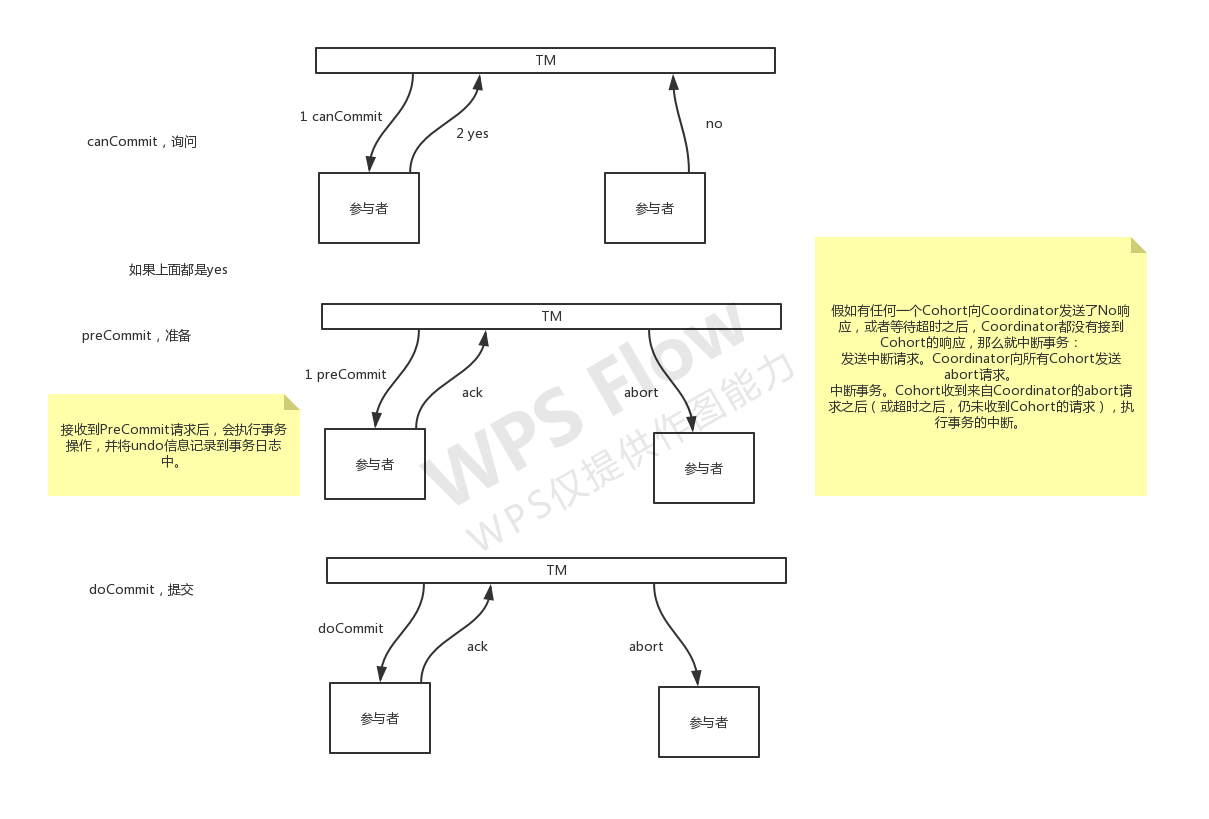
流程
1 | 1.CanCommit阶段 |
缺点
如果进入PreCommit后,Coordinator发出的是abort请求,假设只有一个Cohort收到并进行了abort操作,
而其他对于系统状态未知的Cohort会根据3PC选择继续Commit,此时系统状态发生不一致性。
2和3 的区别
加了询问,增大成功概率。
对于协调者(Coordinator)和参与者(Cohort)都设置了超时机制(在2PC中,只有协调者拥有超时机制,即如果在一定时间内没有收到cohort的消息则默认失败)。协调者挂了,参与者等待超时后,默认提交事务。有一丢进步。
如果参与者异常了,协调者也异常了,会造成其他参与者提交。
在2PC的准备阶段和提交阶段之间,插入预提交阶段,使3PC拥有CanCommit、PreCommit、DoCommit三个阶段。
PreCommit是一个缓冲,保证了在最后提交阶段之前各参与节点的状态是一致的。
基于消息的最终一致性形式
采取最终一致性,遵从BASE理论。
BASE:全称是,Basically Avaliable(基本可用),Soft state(软状态),Eventually consistent(最终一致性)三个短语的缩写,来自eBay的架构师提出。
- Basically Avaliable:就是在分布式系统环境中,允许牺牲掉部分不影响主流程的功能的不可用,将其降级以确保核心服务的正常可用。
- Soft state:就是指在事务中,我们允许系统存在中间状态,且并不影响我们这个系统。就拿数据库的主从复制来说,是完全允许复制的时候有延时的发生的。
- Eventually consistent:还是以数据库主从复制为例说,虽然主从复制有小延迟,但是很快最终就数据保持一致了。
分布式事务不可能100%解决,只能提高成功概率。两阶段之间时间,毫秒级别。
补救措施:
定时任务补偿。程序或脚本补偿。
人工介入。
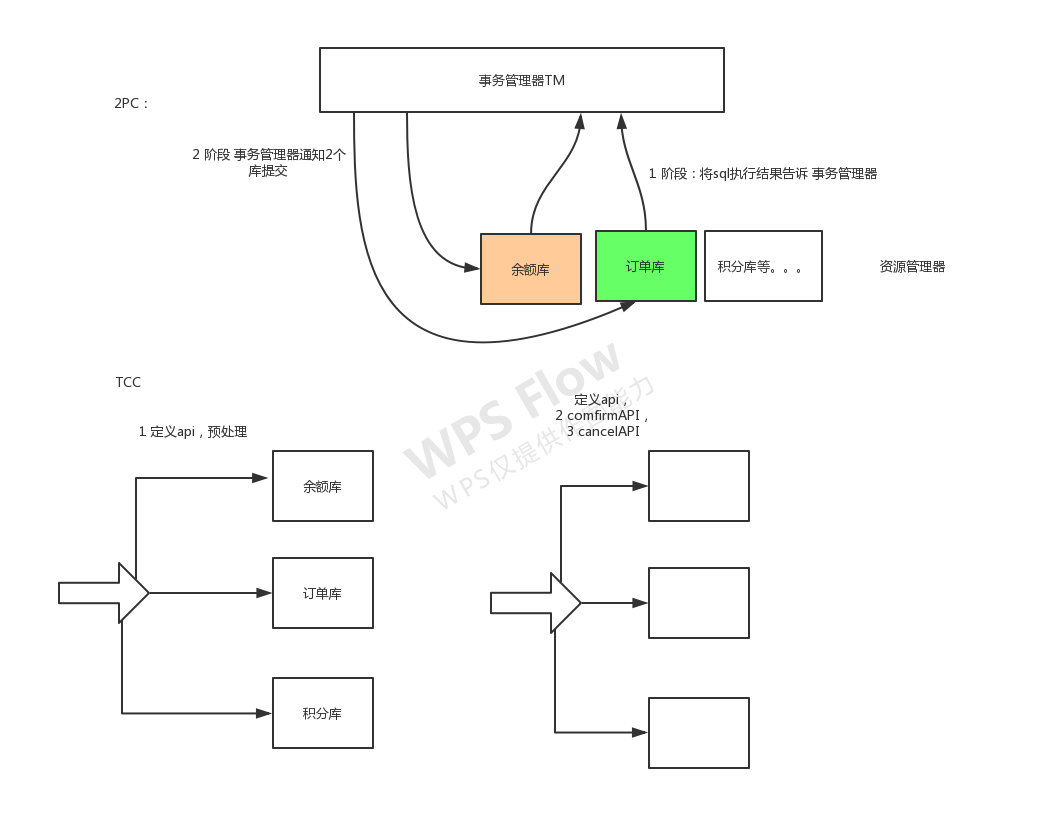
TCC
解决方案:TCC(Try、Confirm、Cancel),两阶段补偿型方案。
从名字可以看出,实现一个事务,需要定义三个API:预先占有资源,确认提交实际操作资源,取消占有=回滚。
如果后两个环节执行一半失败了,记录日志,补偿处理,通知人工。
1 | 2PC:是资源层面的分布式事务,一直会持有资源的锁。 |
消息中间件实现
1 | http://localhost:8161/index.html |
《消息队列柔性事务》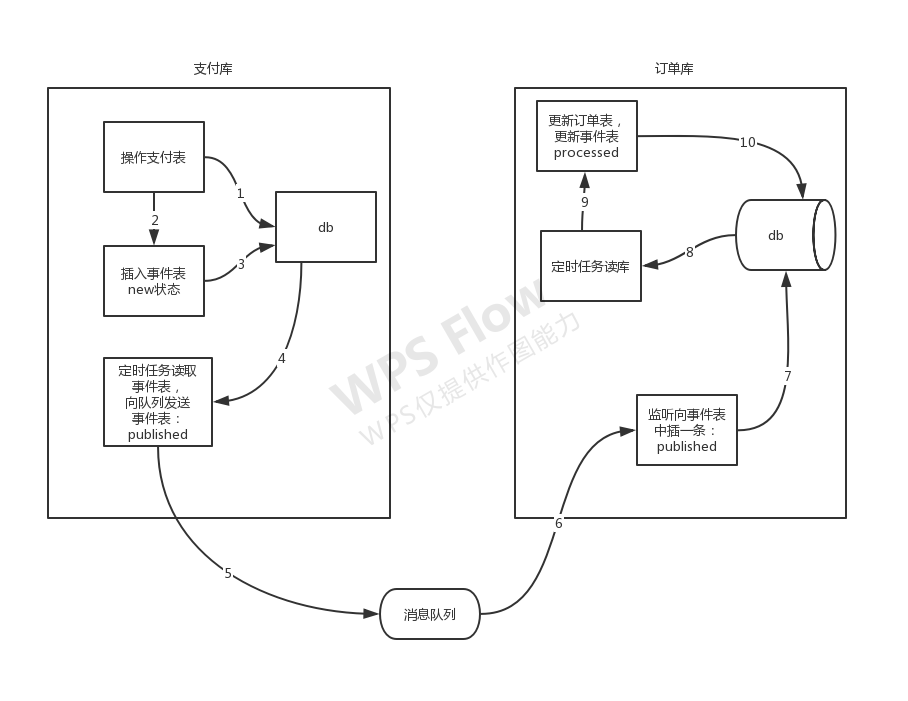
service-jms-consumer
service-jms-produce
本地事务+定时任务+消息队列+事件表
1 | CREATE TABLE `tbl_order_event` ( |
seata框架
https://seata.io/zh-cn/docs/overview/what-is-seata.html
《seata组件功能示意图》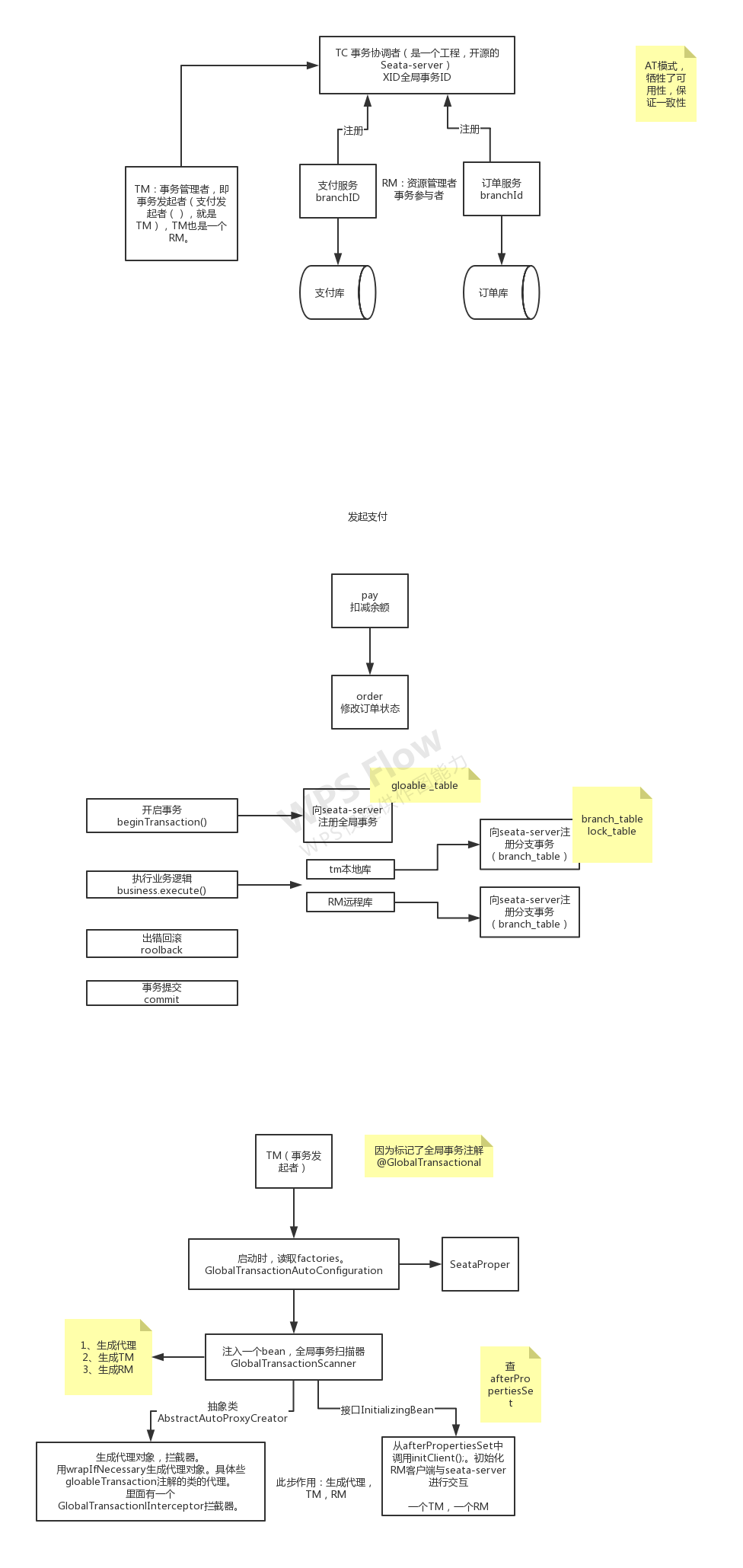
链接介绍概念
启动server:
1 | C:\github\seata\bin |
地址:
1 | localhost:8001/test/rm1 |
使用
下载seata server。
修改file.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36service {
#transaction service group mapping
#修改,可不改,my_test_tx_group随便起名字。
vgroup_mapping.my_test_tx_group = "default"
#only support when registry.type=file, please don't set multiple addresses
# 此服务的地址
default.grouplist = "127.0.0.1:8091"
#disable seata
disableGlobalTransaction = false
}
store {
## store mode: file、db
# 修改
mode = "db"
## file store property
file {
## store location dir
dir = "sessionStore"
}
## database store property
#db信息修改
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp) etc.
datasource = "druid"
## mysql/oracle/h2/oceanbase etc.
db-type = "mysql"
driver-class-name = "com.mysql.cj.jdbc.Driver"
url = "jdbc:mysql://127.0.0.1:3306/seata-server?useUnicode=true&useSSL=false&characterEncoding=utf8&serverTimezone=Asia/Shanghai"
user = "root"
password = "root"
}
}registry.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
#修改
type = "eureka"
nacos {
serverAddr = "localhost"
namespace = ""
cluster = "default"
}
#修改
eureka {
serviceUrl = "http://localhost:8761/eureka"
application = "default"
weight = "1"
}
redis {
serverAddr = "localhost:6379"
db = "0"
}
zk {
cluster = "default"
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
}
consul {
cluster = "default"
serverAddr = "127.0.0.1:8500"
}
etcd3 {
cluster = "default"
serverAddr = "http://localhost:2379"
}
sofa {
serverAddr = "127.0.0.1:9603"
application = "default"
region = "DEFAULT_ZONE"
datacenter = "DefaultDataCenter"
cluster = "default"
group = "SEATA_GROUP"
addressWaitTime = "3000"
}
file {
name = "file.conf"
}
}
config {
# file、nacos 、apollo、zk、consul、etcd3
type = "file"
nacos {
serverAddr = "localhost"
namespace = ""
}
consul {
serverAddr = "127.0.0.1:8500"
}
apollo {
app.id = "seata-server"
apollo.meta = "http://192.168.1.204:8801"
}
zk {
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
}
etcd3 {
serverAddr = "http://localhost:2379"
}
file {
name = "file.conf"
}
}创建数据库,并建表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50分支事务表
CREATE TABLE `branch_table` (
`branch_id` bigint(20) NOT NULL,
`xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`transaction_id` bigint(20) DEFAULT NULL,
`resource_group_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`resource_id` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`branch_type` varchar(8) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`status` tinyint(4) DEFAULT NULL,
`client_id` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`gmt_create` datetime DEFAULT NULL,
`gmt_modified` datetime DEFAULT NULL,
PRIMARY KEY (`branch_id`) USING BTREE,
KEY `idx_xid` (`xid`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
全局事务表
CREATE TABLE `global_table` (
`xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`transaction_id` bigint(20) DEFAULT NULL,
`status` tinyint(4) NOT NULL,
`application_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`transaction_service_group` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`transaction_name` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`timeout` int(11) DEFAULT NULL,
`begin_time` bigint(20) DEFAULT NULL,
`application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`gmt_create` datetime DEFAULT NULL,
`gmt_modified` datetime DEFAULT NULL,
PRIMARY KEY (`xid`) USING BTREE,
KEY `idx_gmt_modified_status` (`gmt_modified`,`status`) USING BTREE,
KEY `idx_transaction_id` (`transaction_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
全局锁
CREATE TABLE `lock_table` (
`row_key` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`xid` varchar(96) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`transaction_id` bigint(20) DEFAULT NULL,
`branch_id` bigint(20) NOT NULL,
`resource_id` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`table_name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`pk` varchar(36) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`gmt_create` datetime DEFAULT NULL,
`gmt_modified` datetime DEFAULT NULL,
PRIMARY KEY (`row_key`) USING BTREE,
KEY `idx_branch_id` (`branch_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;表的结构不能错。
接着改RM中的数据库。在每个库中增加。用于回滚。
1
2
3
4
5
6
7
8
9
10
11
12
13
14用于RM回滚的。
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`context` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;启动seata-server,(seata-server.bat),去eureka中看效果。
应用
1. 数据库本地事务
- ACID
- Undo Log -> 原子性 Redo Log -> 持久性
- 锁 -> 隔离性
- AID -> C

2. 分布式事务
3. 两阶段提交
一阶段: 提交请求
协调者 & 参与者
- 协调者向所有参与者发送prepare请求与事务内容,询问是否可以准备事务提交,并等待参与者的响应。
- 参与者执行事务中包含的操作,并记录undo日志(用于回滚)和redo日志(用于重放),但不真正提交。
- 参与者向协调者返回事务操作的执行结果,执行成功返回yes,否则返回no。

二阶段: 提交执行
成功 / 失败两种情况若所有参与者都返回yes,说明事务可以提交:
- 协调者向所有参与者发送commit请求。
- 参与者收到commit请求后,将事务真正地提交上去,并释放占用的事务资源,并向协调者返回ack。
- 协调者收到所有参与者的ack消息,事务成功完成。
若有参与者返回no或者超时未返回,说明事务中断,需要回滚:
- 协调者向所有参与者发送rollback请求。
- 参与者收到rollback请求后,根据undo日志回滚到事务执行前的状态,释放占用的事务资源,并向协调者返回ack。
- 协调者收到所有参与者的ack消息,事务回滚完成。

4. 三阶段提交 (减少资源锁定的时间)
区别于两阶段: 增加超时, 降低不通的可能性, 不能完全避免
二阶段提交看起来确实能够提供原子性的操作,但是不幸的事,二阶段提交还是有几个缺点的:
1、同步阻塞问题。执行过程中,所有参与节点都是事务阻塞型的。当参与者占有公共资源时,其他第三方节点访问公共资源不得不处于阻塞状态。
2、单点故障。由于协调者的重要性,一旦协调者发生故障。参与者会一直阻塞下去。尤其在第二阶段,协调者发生故障,那么所有的参与者还都处于锁定事务资源的状态中,而无法继续完成事务操作。(如果是协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)
3、数据不一致。在二阶段提交的阶段二中,当协调者向参与者发送commit请求之后,发生了局部网络异常或者在发送commit请求过程中协调者发生了故障,这回导致只有一部分参与者接受到了commit请求。而在这部分参与者接到commit请求之后就会执行commit操作。但是其他部分未接到commit请求的机器则无法执行事务提交。于是整个分布式系统便出现了数据部一致性的现象。
4、二阶段无法解决的问题:协调者再发出commit消息之后宕机,而唯一接收到这条消息的参与者同时也宕机了。那么即使协调者通过选举协议产生了新的协调者,这条事务的状态也是不确定的,没人知道事务是否被已经提交。
二阶段提交存在着诸如同步阻塞、单点问题、脑裂等缺陷,所以,研究者们在二阶段提交的基础上做了改进,提出了三阶段提交。
- 对于协调者(Coordinator)和参与者(Cohort)都设置了超时机制(在2PC中,只有协调者拥有超时机制,即如果在一定时间内没有收到cohort的消息则默认失败)。
- 在2PC的准备阶段和提交阶段之间,插入预提交阶段,使3PC拥有CanCommit、PreCommit、DoCommit三个阶段。
- PreCommit是一个缓冲,保证了在最后提交阶段之前各参与节点的状态是一致的。
CanCommit阶段
3PC的CanCommit阶段其实和2PC的准备阶段很像。协调者向参与者发送commit请求,参与者如果可以提交就返回Yes响应,否则返回No响应。
1.事务询问 协调者向参与者发送CanCommit请求。询问是否可以执行事务提交操作。然后开始等待参与者的响应。
2.响应反馈 参与者接到CanCommit请求之后,正常情况下,如果其自身认为可以顺利执行事务,则返回Yes响应,并进入预备状态。否则反馈No
PreCommit阶段 (资源锁定)协调者根据参与者的反应情况来决定是否可以记性事务的PreCommit操作。根据响应情况,有以下两种可能。
假如协调者从所有的参与者获得的反馈都是Yes响应,那么就会执行事务的预执行。
1.发送预提交请求 协调者向参与者发送PreCommit请求,并进入Prepared阶段。
2.事务预提交 参与者接收到PreCommit请求后,会执行事务操作,并将undo和redo信息记录到事务日志中。
3.响应反馈 如果参与者成功的执行了事务操作,则返回ACK响应,同时开始等待最终指令。
假如有任何一个参与者向协调者发送了No响应,或者等待超时之后,协调者都没有接到参与者的响应,那么就执行事务的中断。1.发送中断请求 协调者向所有参与者发送abort请求。
2.中断事务 参与者收到来自协调者的abort请求之后(或超时之后,仍未收到协调者的请求),执行事务的中断。
doCommit阶段
该阶段进行真正的事务提交,也可以分为以下两种情况。
执行提交
1.发送提交请求 协调接收到参与者发送的ACK响应,那么他将从预提交状态进入到提交状态。并向所有参与者发送doCommit请求。
2.事务提交 参与者接收到doCommit请求之后,执行正式的事务提交。并在完成事务提交之后释放所有事务资源。
3.响应反馈 事务提交完之后,向协调者发送Ack响应。
4.完成事务 协调者接收到所有参与者的ack响应之后,完成事务。
中断事务 协调者没有接收到参与者发送的ACK响应(可能是接受者发送的不是ACK响应,也可能响应超时),那么就会执行中断事务。
1.发送中断请求 协调者向所有参与者发送abort请求
2.事务回滚 参与者接收到abort请求之后,利用其在阶段二记录的undo信息来执行事务的回滚操作,并在完成回滚之后释放所有的事务资源。
3.反馈结果 参与者完成事务回滚之后,向协调者发送ACK消息
4.中断事务 协调者接收到参与者反馈的ACK消息之后,执行事务的中断。
在doCommit阶段,如果参与者无法及时接收到来自协调者的doCommit或者rebort请求时,会在等待超时之后,会继续进行事务的提交。(其实这个应该是基于概率来决定的,当进入第三阶段时,说明参与者在第二阶段已经收到了PreCommit请求,那么协调者产生PreCommit请求的前提条件是他在第二阶段开始之前,收到所有参与者的CanCommit响应都是Yes。(一旦参与者收到了PreCommit,意味他知道大家其实都同意修改了)所以,一句话概括就是,当进入第三阶段时,由于网络超时等原因,虽然参与者没有收到commit或者abort响应,但是他有理由相信:成功提交的几率很大。 )
5. CAP 理论
6. BASE 理论
7. 消息队列 + 事件表 手动实现分布式事务
不适用大数据量
双事件表, 双定时


支付系统
2-3 发送消息队列失败, 可以集体回滚
事件表: 三级等保, 保留6个月数据
第三方回调信息: 计算回调成功率


1 | /** |
订单系统


- 3-1 监听 3-2 入库, 成功: 3-3 返回 mq.ack, 失败: 3-2 回滚, 3-3 恢复消息 mq.recovery
- 消息事件ID, 解决重复消费问题
- 消息队列存 Json 格式的数据
1 | /** |