Redis的前世今生
基本介绍
数据存储演变过程
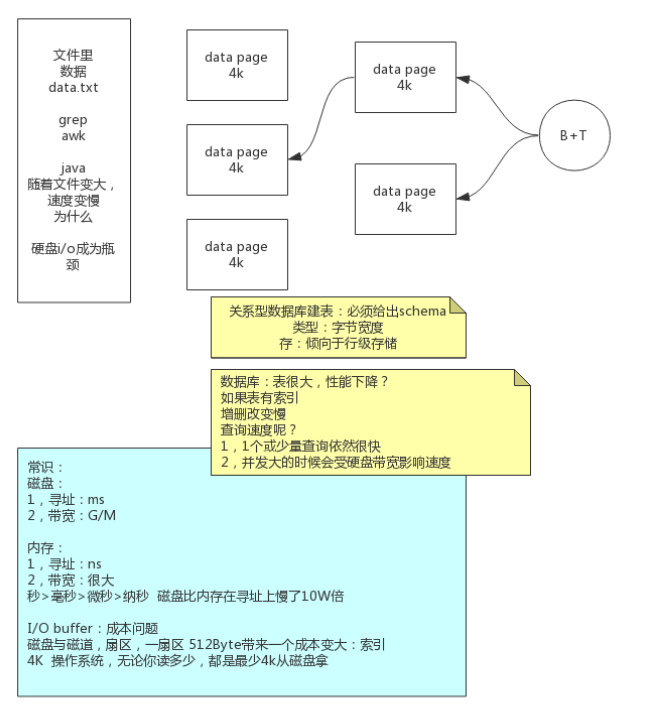
- 数据存储在文件中:查找数据造成全量扫描,受限于磁盘IO的瓶颈
- 关系型数据库:关系型数据库是行级存储,会空出来没有数据列,受限于磁盘IO的瓶颈
- 数据库放入缓存:受限于硬件,成本高
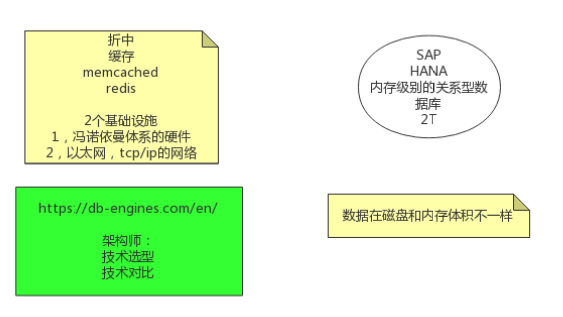
数据的存储方式受限于:
- 冯诺依曼体系的硬件制约
- 以太网, TCP/IP 的网络
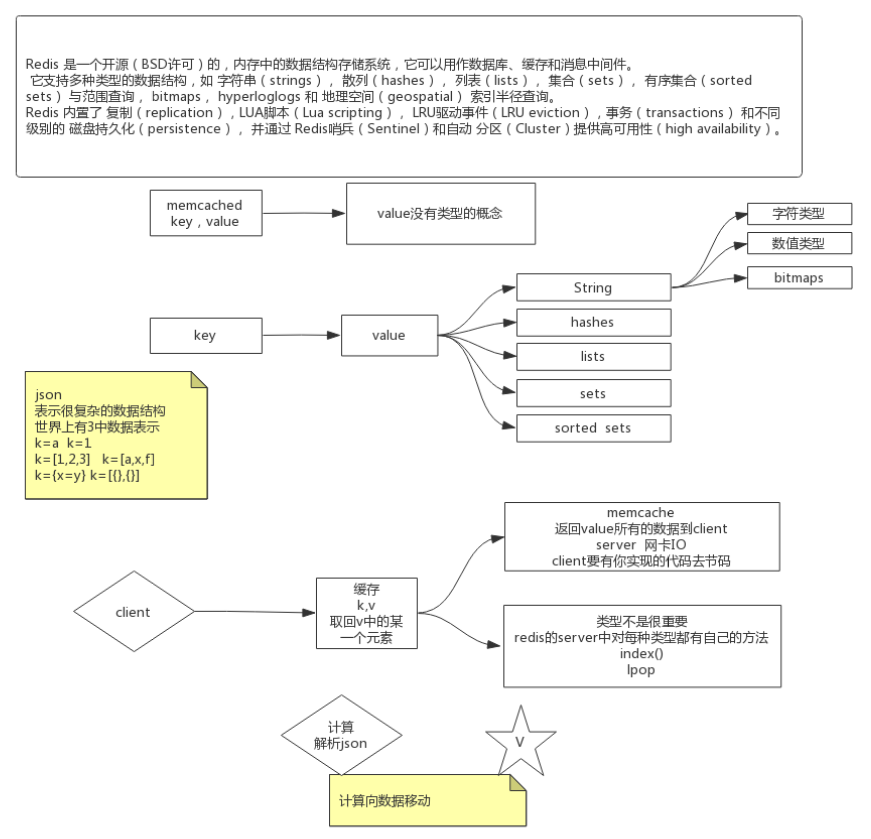
Redis的特点,对比Memcache , value有类型 , 有类型对应的方法(API) , 计算向数据移动
安装

1 | centos 6.x |
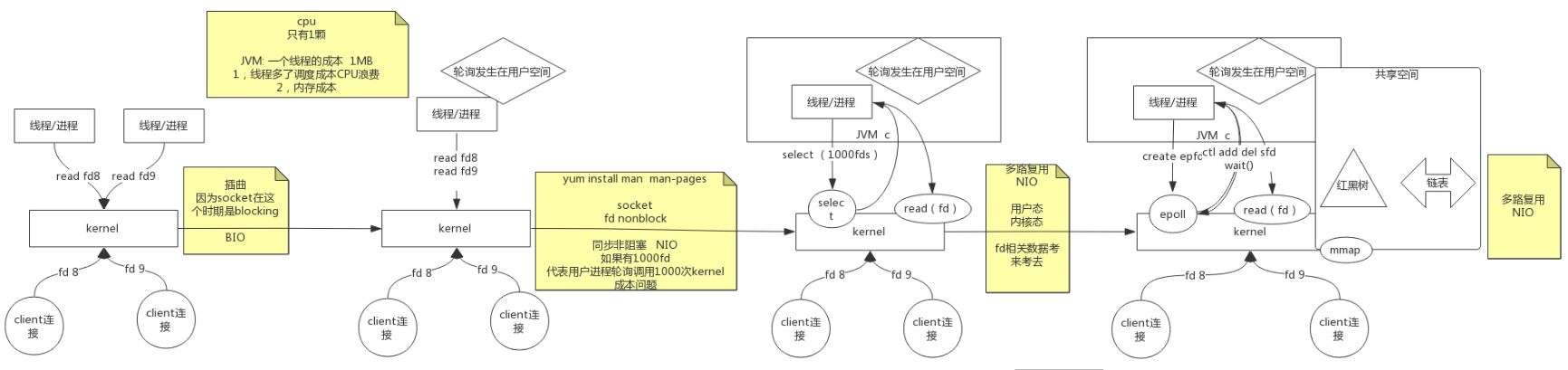
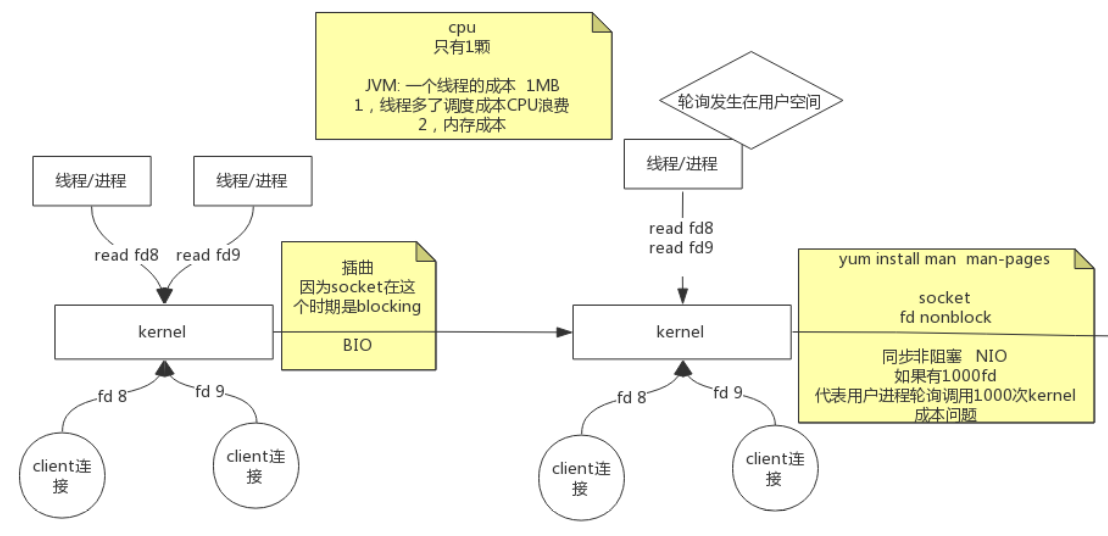
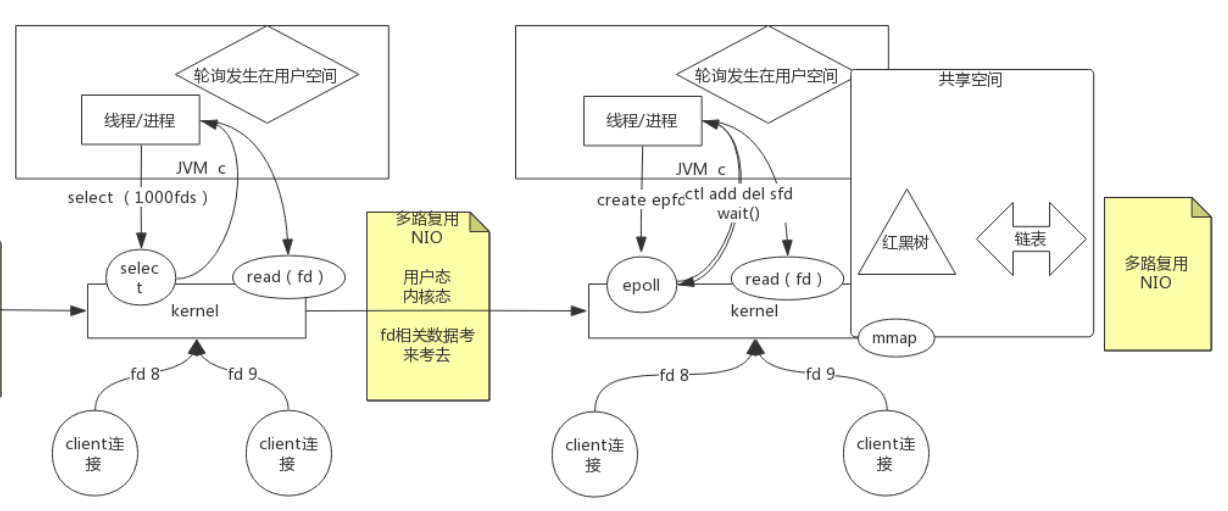
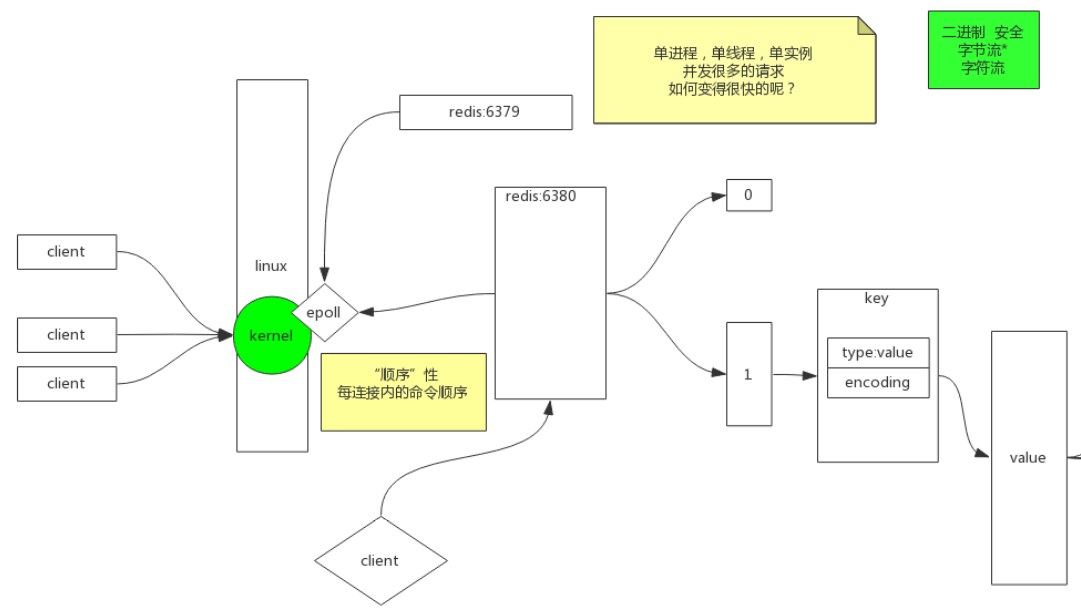
BIO->同步非阻塞NIO->多路复用NIO
内核不断变化
- BIO阻塞: 读一个socket产生的文件描述符, 如果数据包没到, read命令就不能返回, 在这阻塞着, 抛出一个线程在这阻塞着, 有数据就处理, 下边的代码执行不了, 其他线程无法处理已到达的数据, socket是阻塞的
一个线程的成本: 线程栈是独立的, 默认1MB, 线程多了, 调度成本提高. CPU浪费, 占用内存多 - 同步非阻塞NIO: 遍历, 取出来处理, 都由自己来完成, 同步非阻塞, 每个连接都要掉一次内核
- 多路复用NIO: 内核select(), 允许一个程序监视多个文件描述符, 等待直到一个或多个文件描述符准备好, 就能触发I/O操作了 , 一次系统调用读若干个, 返回有数据的, 减少用户态内核态切换 , 选择有数据的, 直接读
- 共享空间: 文件描述符都是累赘, 减少内核区域和用户空间之间传参, 把用户空间和内核空间建立映射, 相当于创建共享空间, 通过mmap系统调用, 红黑树+链表, 进程里有文件描述符就往红黑树里放, 内核可以看到, 把到达的放到链表里, 如果
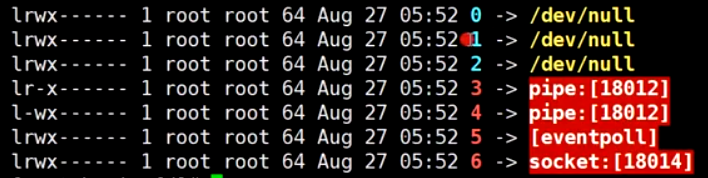
Redis进程的文件描述符
0: 标准输入 1: 标准输出 2: 报错输出 3,4: pipe调用 5: epoll
kafka: sendfile + mmap
零拷贝: sendfile系统调用
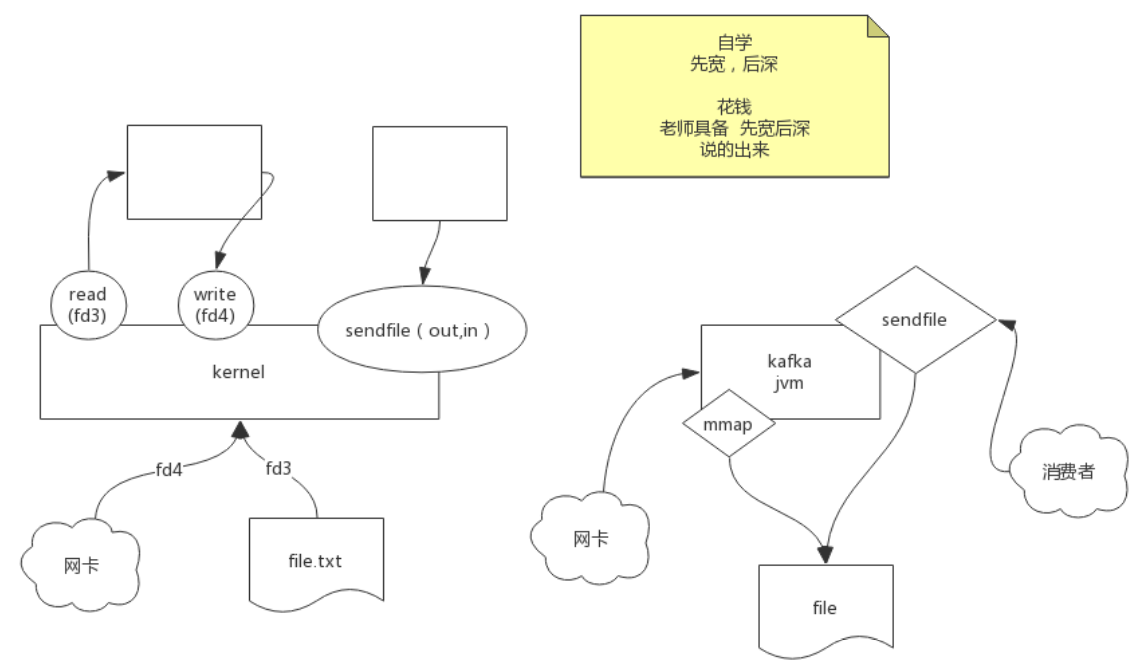
Redis为什么快: epoll : epoll是 Linux内核 为处理大批量 文件描述符 而作了改进的poll,是Linux下多路复用IO接口select/poll的增强版本,它能显著提高程序在大量 并发连接 中只有少量活跃的情况下的系统 CPU利用率。另一点原因就是获取事件的时候,它无须遍历整个被侦听的描述符集,只要遍历那些被内核IO事件异步唤醒而加入Ready队列的描述符集合就行了。
顺序性: 每个连接内的命令顺序
内存寻址是ns级, 网卡是ms级, 10万倍差距, 10万连接同时时到达, 可能会产生秒级响应
mysql开启缓存, 想模仿redis, 性能反而会低, 多了一次判断过程, 增加了内存空间占用
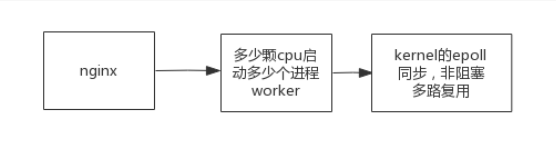
类比Nginx
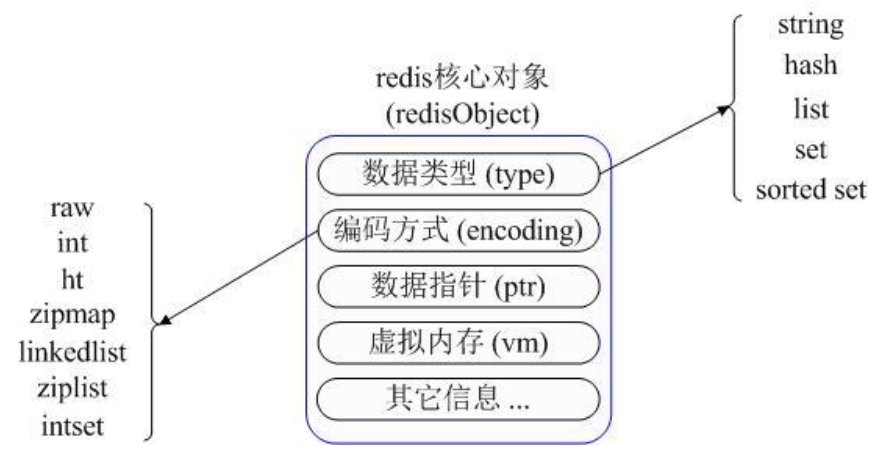
5种数据类型
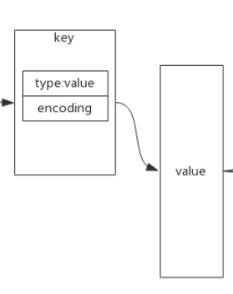
可以根据用户的指令, 看是不是和key里存的type匹配, 不匹配直接返回, 规避异常
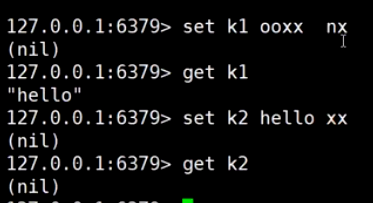
nx: 只能新建 分布式锁
xx: 只能更新
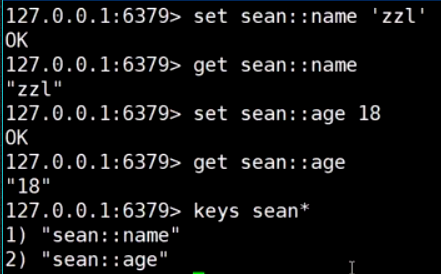
String
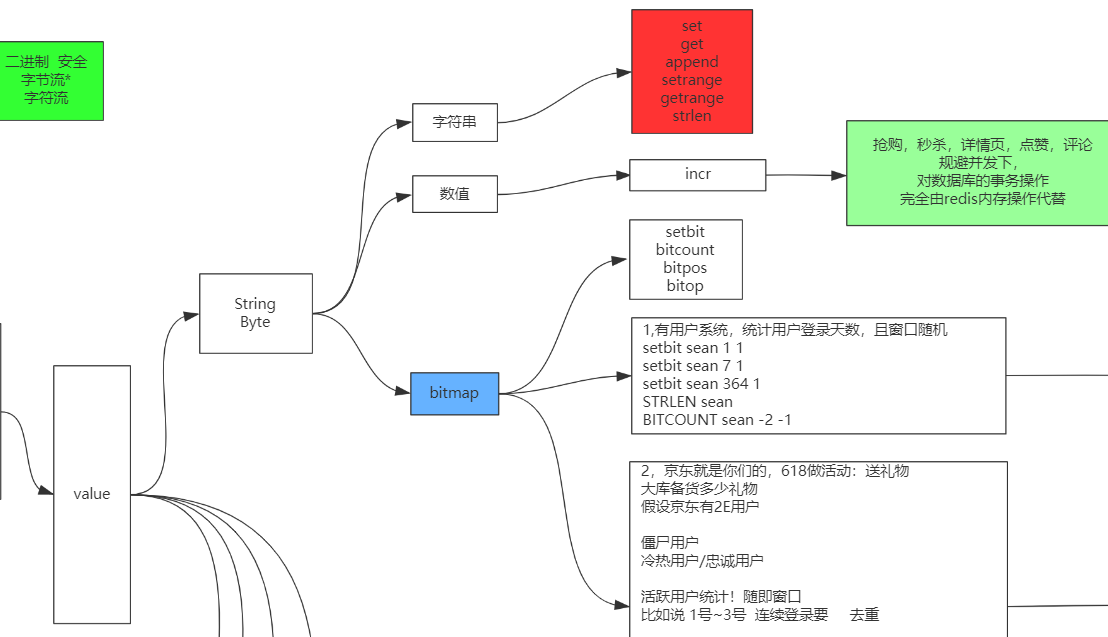
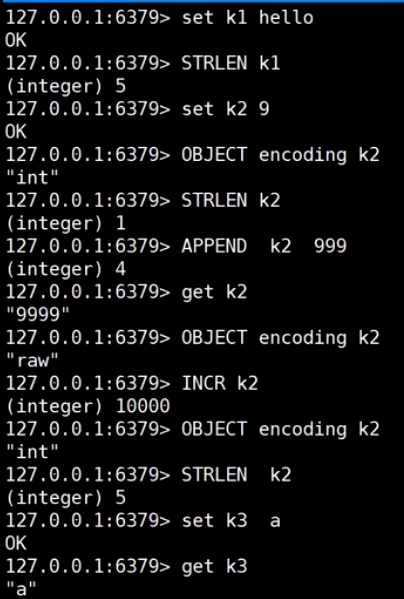
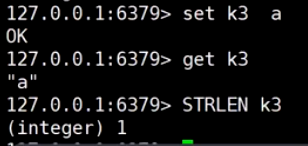
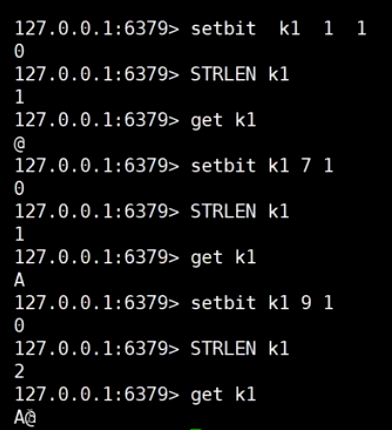
二进制安全: Redis只取字节流, 一个字符一个字节

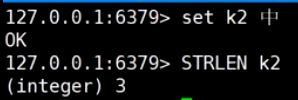
和Xshell设置有关
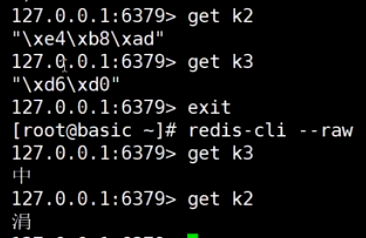
GETSET减少一次I/O
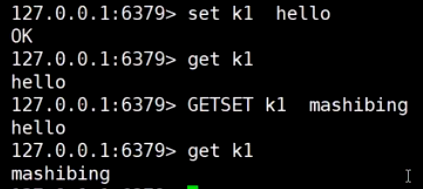
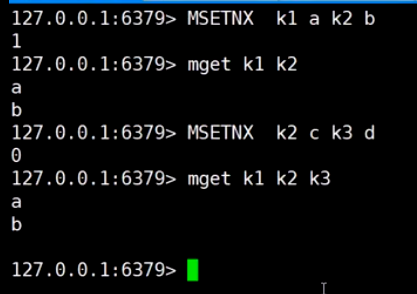
MSETNX原子性set, k2已经存在, 集体失败
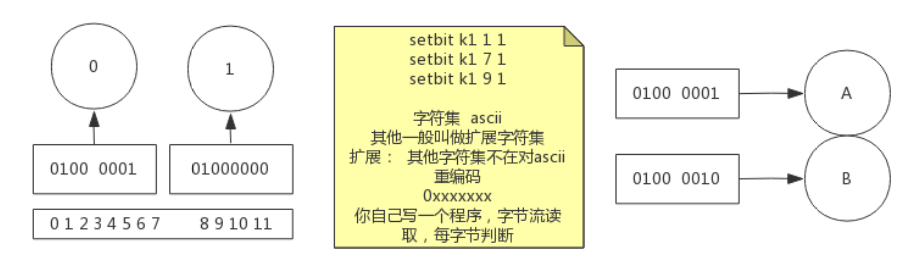
bitmap (活跃度|登录数)
按位与
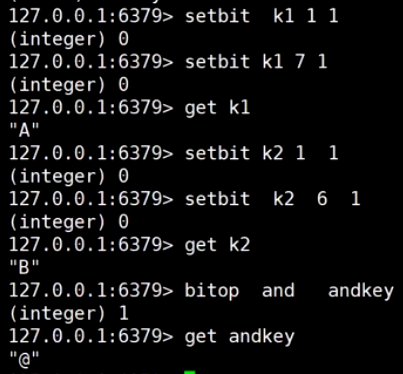
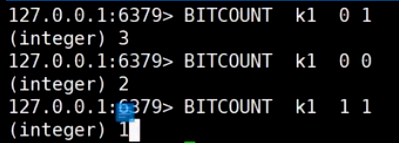
bitmap优势, 举例: 统计用户登录, 按位与, 统计365天, key是天
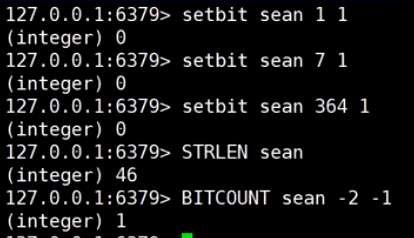
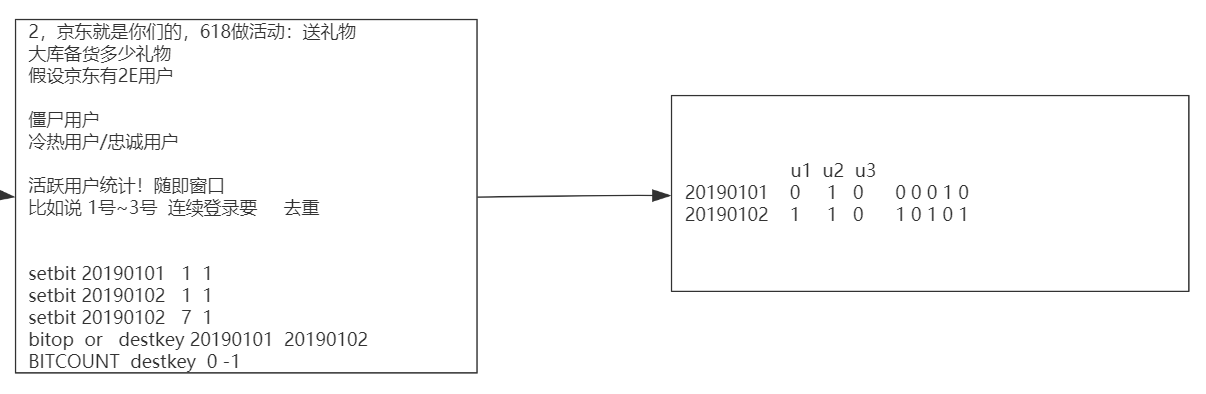
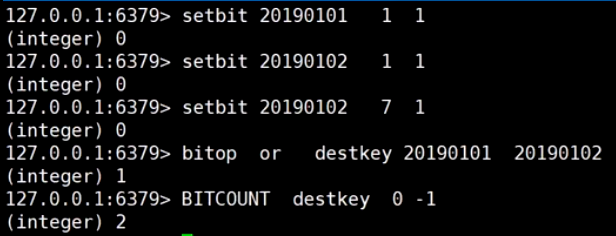
举例: 共计活跃用户数
第一天a登录, 第二天ab都登陆, 按位或统计活跃用户数, key是日期, value是用户登录情况
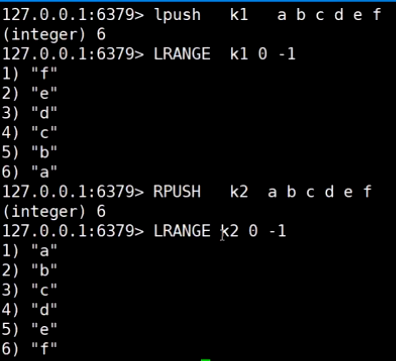
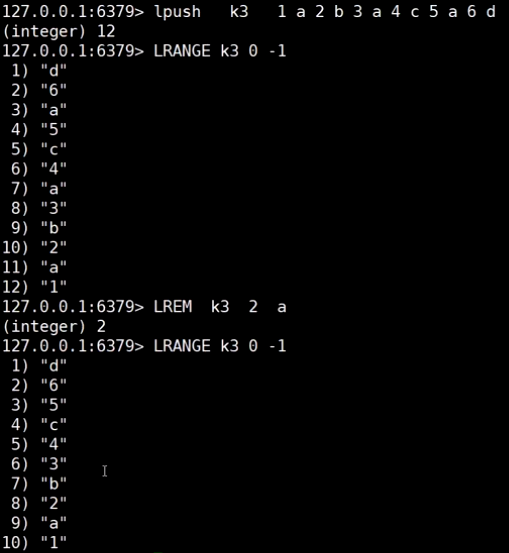
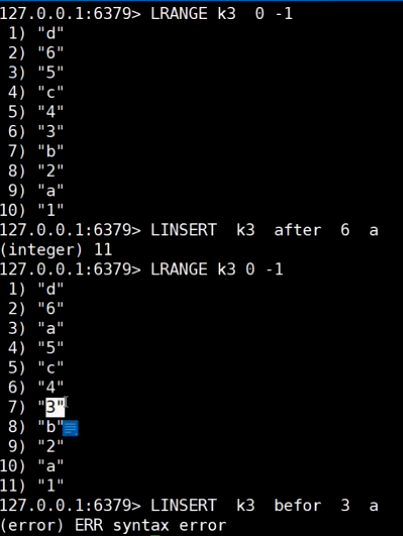
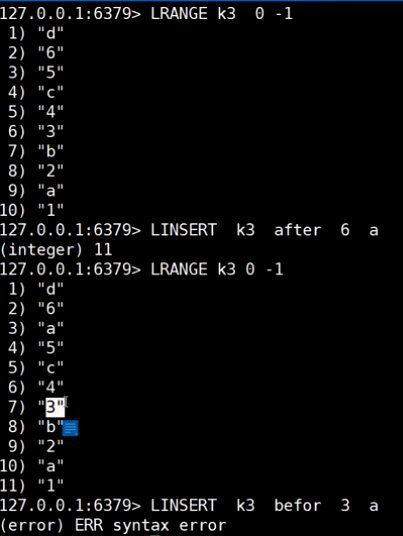
list (栈|队列)
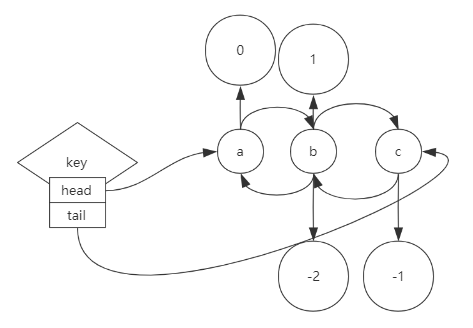
同向操作: 栈
反向操作: 队列
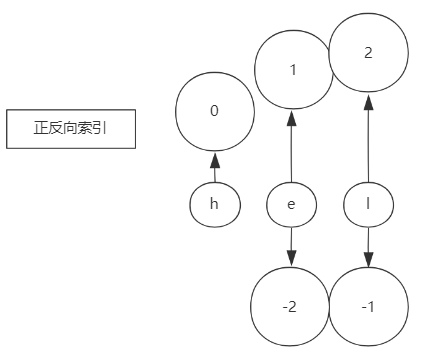
正反索引
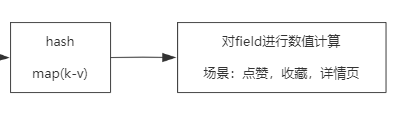
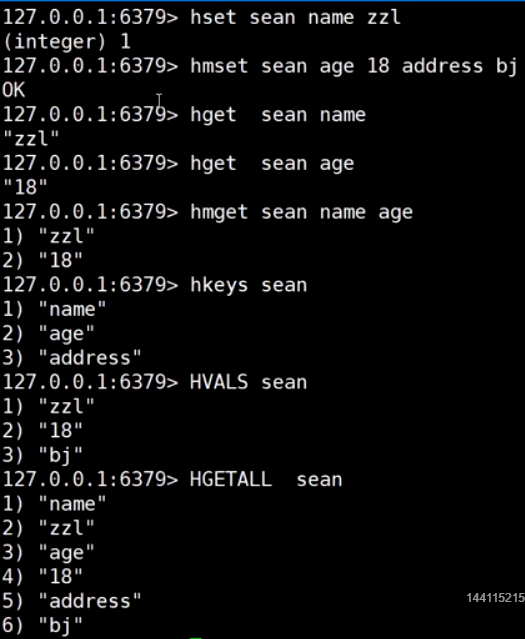
hash (点赞|收藏|详情页)
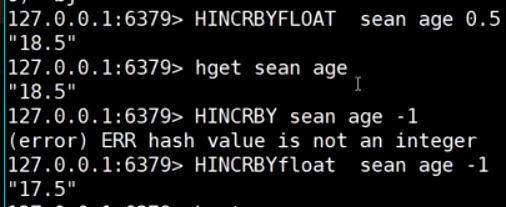
set (交并差集)
取交集
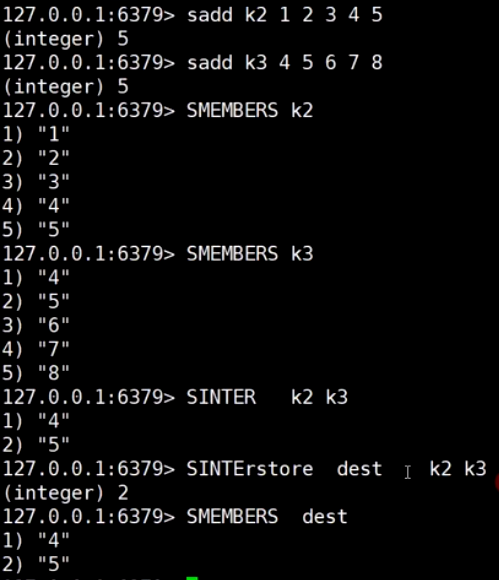
取并集
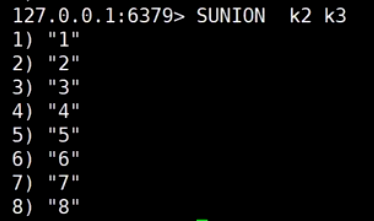
取外差
取随机, 抽奖, 正数不可重复出现, 负数可重复出现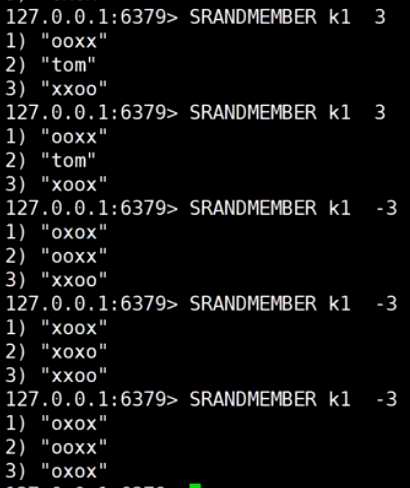
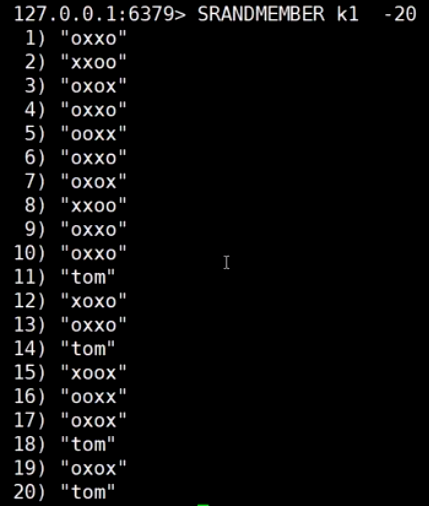
spop随机抽
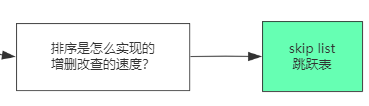
sorted set (排行榜)
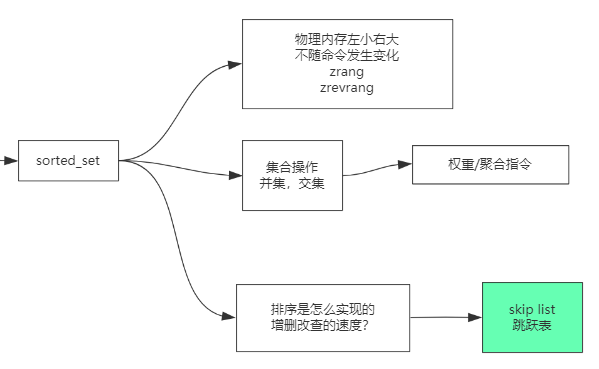
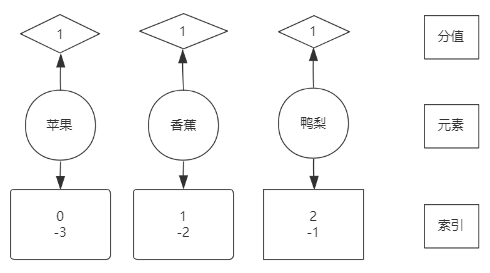
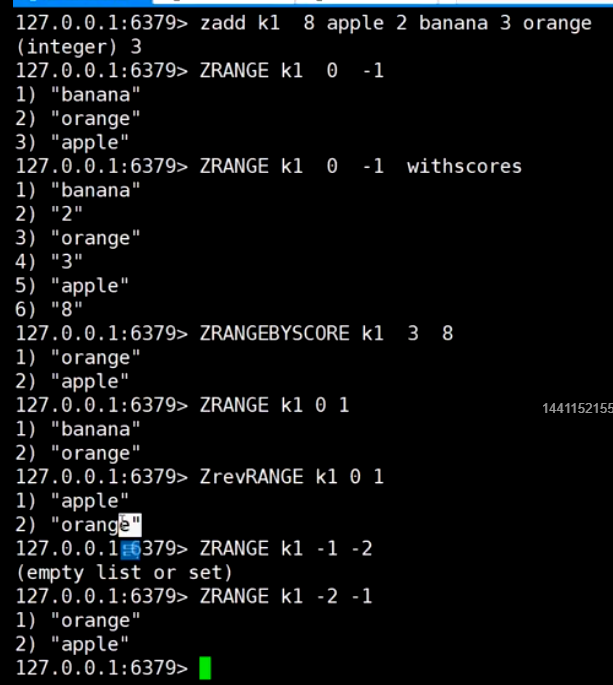
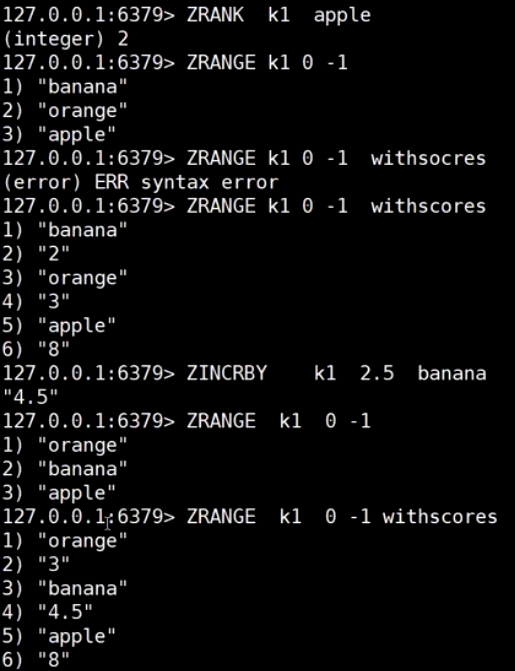
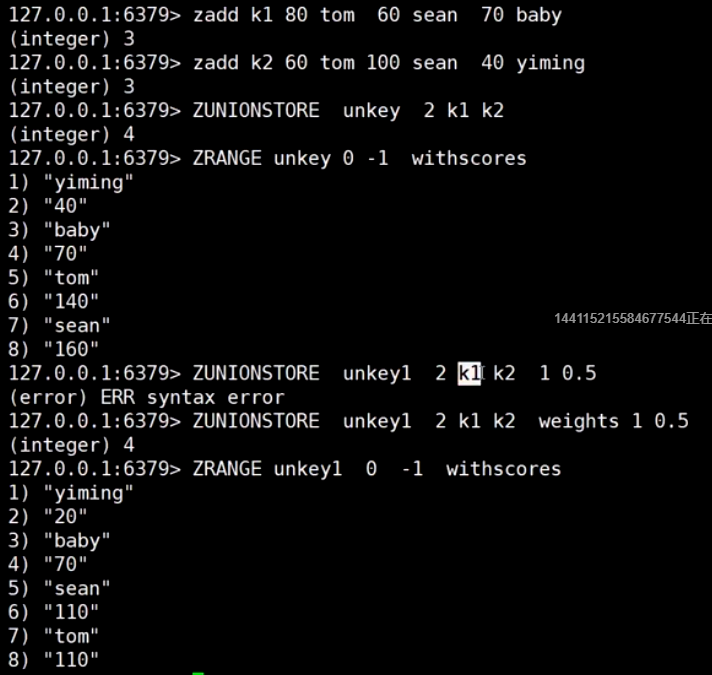
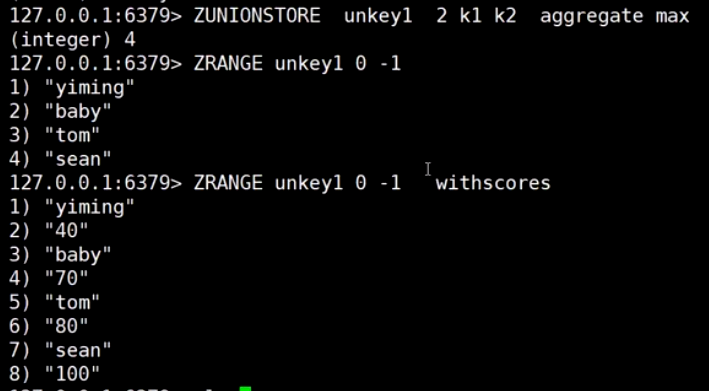
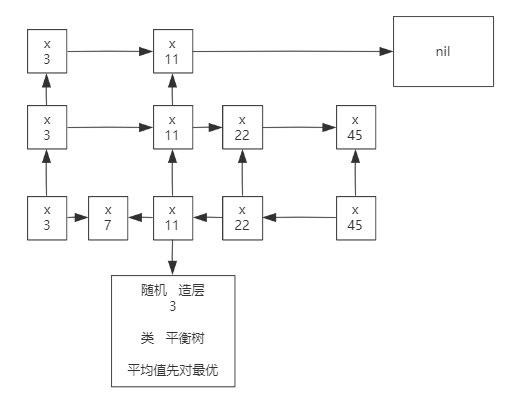
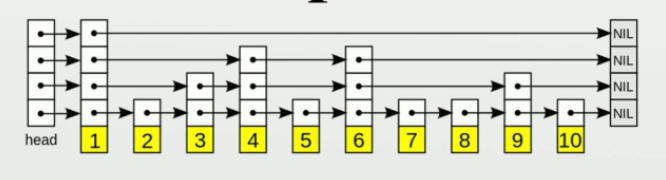
跳表 (随机造层)
图错了
进阶使用
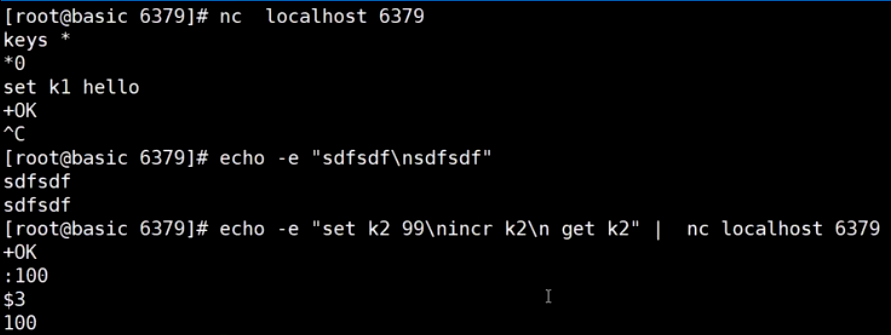
管道Pipeline
客户端连接服务端:
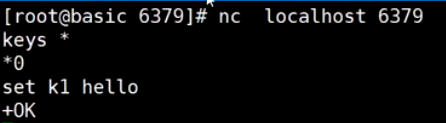
redis 管道 pipeline 一次多条指令
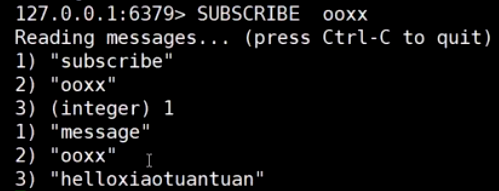
订阅发布
订阅发布, 订阅之后才能收到发布的消息

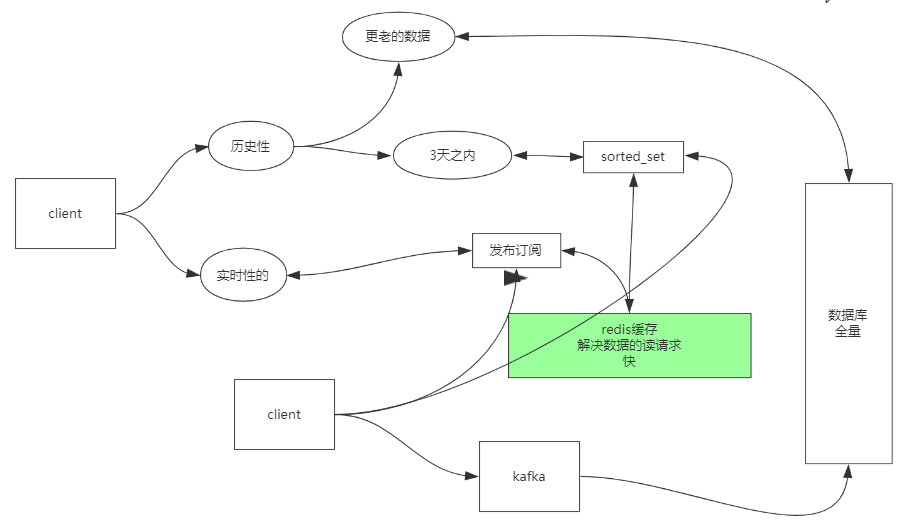
客户端读历史消息和实时消息
redis实时消息, sorted list 日期排序,
聊天室 : Redis+DB
接收消息:
- 实时的消息: 通过发布订阅
- 3天内: sorted_set, 时间作为分值, 消息作为元素
- 历史记录: DB
发送消息:
- 一份直接发到Redis的发布订阅, 一份通过Kafka写到数据库
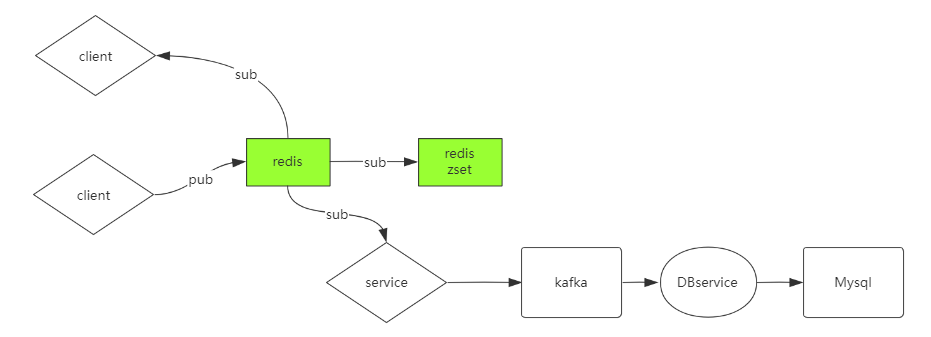
第二种方式实现聊天室: 双实例
Redis事务(无回滚)
- muti: 开启事务, 所有指令按客户端排队
- exec: 执行事务(哪个客户端的exec先来, 先执行谁的所有指令)
- watch: 开启事务之前, 监控某个元素, 发现被更改, 后续相关指令不执行
- DISCARD: 放弃执行事务, 清空事务队列

演示事务
客户端1: 后开启事务, 删除k1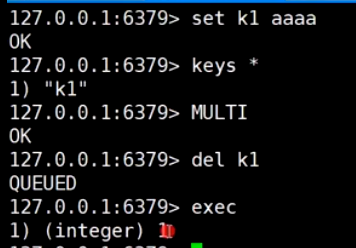
客户端2: 先开启事务, get不到k1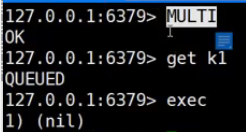
演示watch: k1改了, 事务不执行
客户端1: 由于k1的值被更改, 相关命令不执行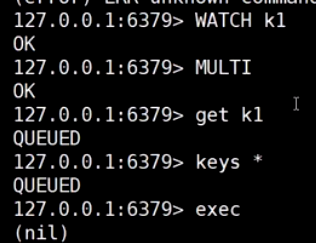
客户端2: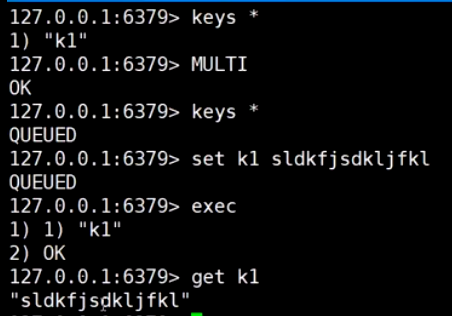
不支持回滚
- Redis 命令只会因为错误的语法而失败(并且这些问题不能在入队时发现),或是命令用在了错误类型的键上面:这也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该出现在生产环境中。
- 因为不需要对回滚进行支持,所以 Redis 的内部可以保持简单且快速。
有种观点认为 Redis 处理事务的做法会产生 bug , 然而需要注意的是, 在通常情况下, 回滚并不能解决编程错误带来的问题。 举个例子, 如果你本来想通过 INCR 命令将键的值加上 1 , 却不小心加上了 2 , 又或者对错误类型的键执行了 INCR , 回滚是没有办法处理这些情况的。](../image/Redis/image-20200410061754103.png)
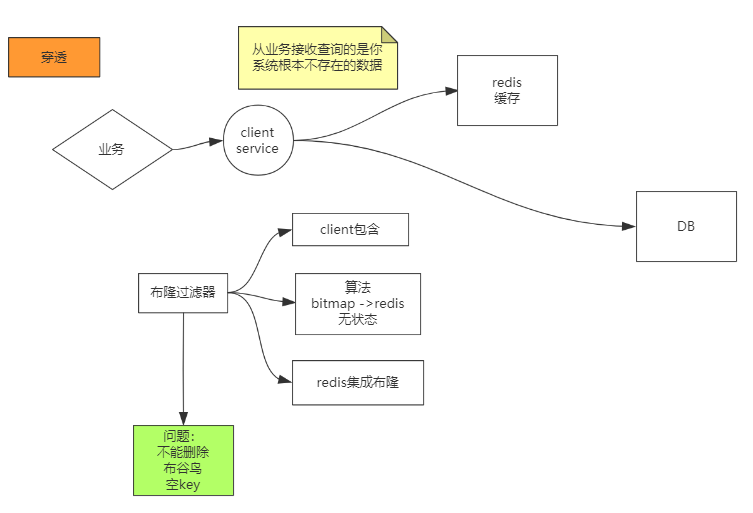
布隆过滤器
启动Redis时, 添加布隆过滤器的扩展库
通过bitmap二进制位数组+映射函数
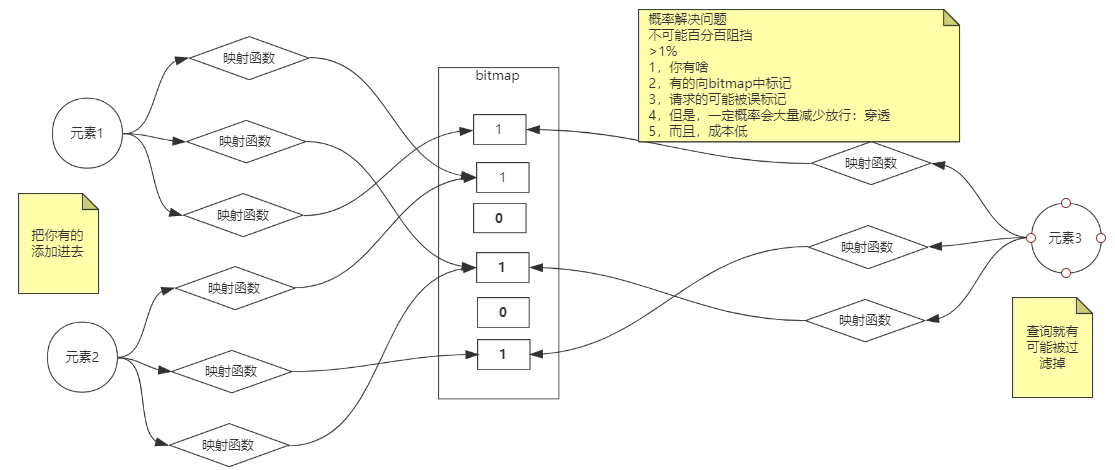
三种方式, 最好放在服务端
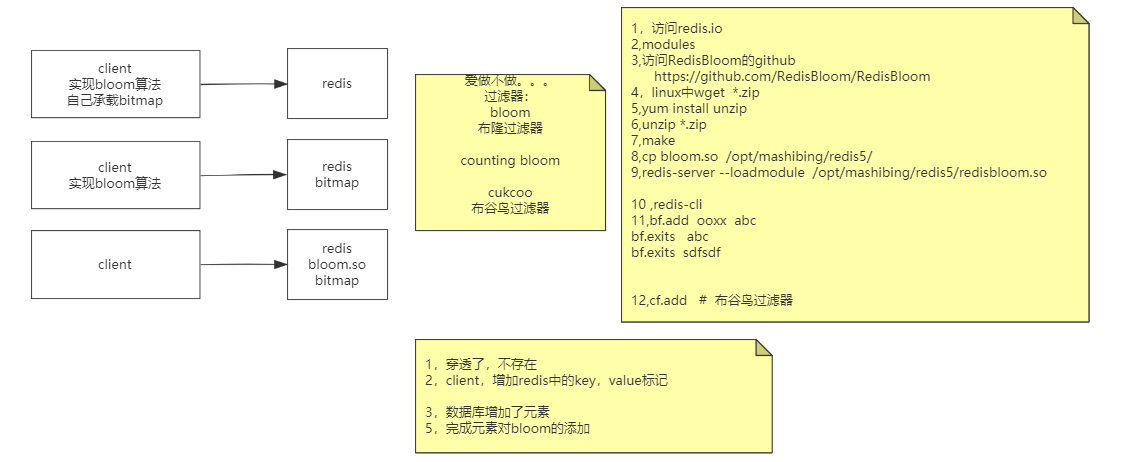
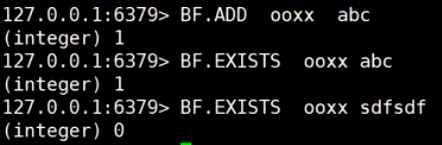
安装
1 | 1,访问redis.io |
Redis作为缓存和数据库的区别

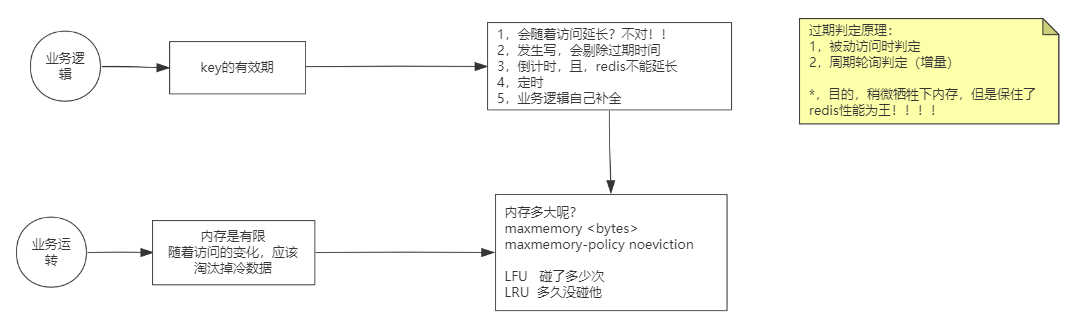
Redis回收策略
过期判定原理:
- 被动访问时判定
- 周期轮询判定(增量)
*,目的,稍微牺牲下内存,但是保住了redis性能为王!!!!
Maxmemory配置指令
maxmemory配置指令用于配置Redis存储数据时指定限制的内存大小。通过redis.conf可以设置该指令,或者之后使用CONFIG SET命令来进行运行时配置。
例如为了配置内存限制为100mb,以下的指令可以放在redis.conf文件中。
1 | maxmemory 100mb |
当指定的内存限制大小达到时,需要选择不同的行为,也就是策略。
回收策略
当maxmemory限制达到的时候Redis会使用的行为由 Redis的maxmemory-policy配置指令来进行配置。
以下的策略是可用的:
- noeviction(默认):返回错误当内存限制达到并且客户端尝试执行会让更多内存被使用的命令(大部分的写入指令,但DEL和几个例外)
- allkeys-lru: 尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。
- volatile-lru: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。
- allkeys-random: 回收随机的键使得新添加的数据有空间存放。
- volatile-random: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
- volatile-ttl: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。
如果没有键满足回收的前提条件的话,策略volatile-lru, volatile-random以及volatile-ttl就和noeviction 差不多了。
一般的经验规则:
- 使用allkeys-lru策略:当你希望你的请求符合一个幂定律分布,也就是说,你希望部分的子集元素将比其它其它元素被访问的更多。如果你不确定选择什么,这是个很好的选择。.
- 使用allkeys-random:如果你是循环访问,所有的键被连续的扫描,或者你希望请求分布正常(所有元素被访问的概率都差不多)。
- 使用volatile-ttl:如果你想要通过创建缓存对象时设置TTL值,来决定哪些对象应该被过期。
allkeys-lru 和 volatile-random策略对于当你想要单一的实例实现缓存及持久化一些键时很有用。不过一般运行两个实例是解决这个问题的更好方法。
为了键设置过期时间也是需要消耗内存的,所以使用allkeys-lru这种策略更加高效,因为没有必要为键取设置过期时间当内存有压力时。
回收进程如何工作
理解回收进程如何工作是非常重要的:
- 一个客户端运行了新的命令,添加了新的数据。
- Redi检查内存使用情况,如果大于maxmemory的限制, 则根据设定好的策略进行回收。
- 一个新的命令被执行,等等。
- 所以我们不断地穿越内存限制的边界,通过不断达到边界然后不断地回收回到边界以下。
如果一个命令的结果导致大量内存被使用(例如很大的集合的交集保存到一个新的键),不用多久内存限制就会被这个内存使用量超越。
近似LRU算法
Redis的LRU算法并非完整的实现。这意味着Redis并没办法选择最佳候选来进行回收,也就是最久未被访问的键。相反它会尝试运行一个近似LRU的算法,通过对少量keys进行取样,然后回收其中一个最好的key(被访问时间较早的)。
不过从Redis 3.0算法已经改进为回收键的候选池子。这改善了算法的性能,使得更加近似真是的LRU算法的行为。
Redis LRU有个很重要的点,你通过调整每次回收时检查的采样数量,以实现调整算法的精度。这个参数可以通过以下的配置指令调整:
1 | maxmemory-samples 5 |

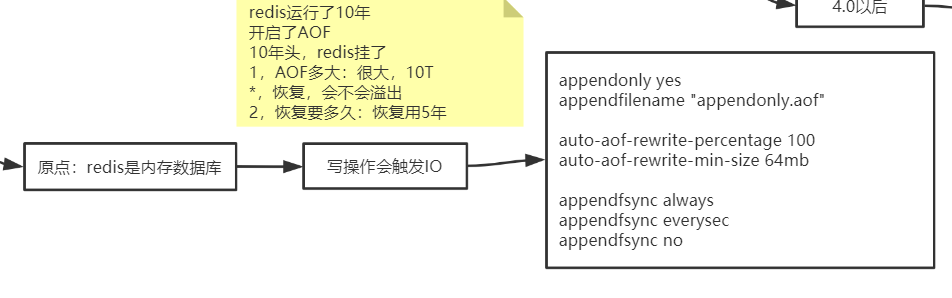
Redis持久化 (重点!!!)

RDB
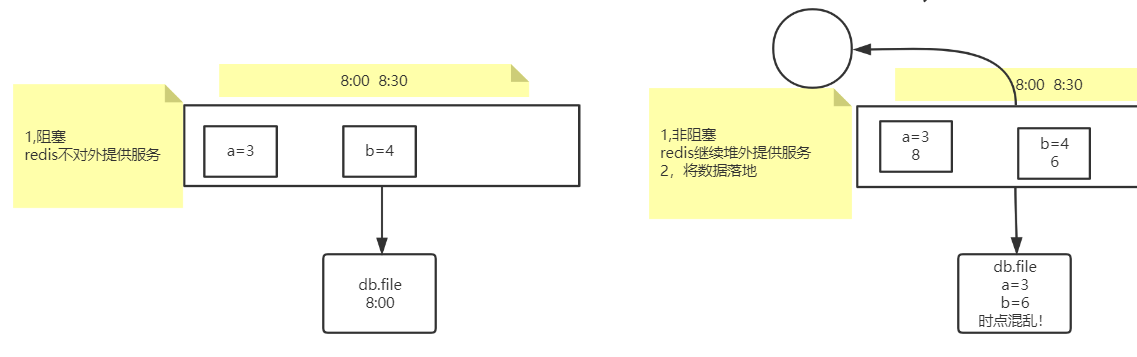
时点混乱
持久化的开始后, 还要记录现在修改的值
管道:
Linux管道概念: 前边命令的输出作为后边命令的输入
1,衔接,前一个命令的输出作为后一个命令的输入
2,管道会触发创建【子进程】
echo $$ | more
echo $BASHPID | more
$$ 高于 |
- 使用linux的时候:存在父子进程
- 父进程的数据,子进程可不可以看得到?
- 常规思想,进程是数据隔离的!
- 进阶思想,父进程其实可以让子进程看到数据!
- linux中export的环境变量,子进程的修改不会破坏父进程, 父进程的修改也不会破坏子进程
写时复制
copy on write:内核机制
fork(): 系统调用
写时复制, 创建子进程并不发生复制
创建进程变快了
根据经验,不可能父子进程把所有数据都改一遍, 玩的是指针
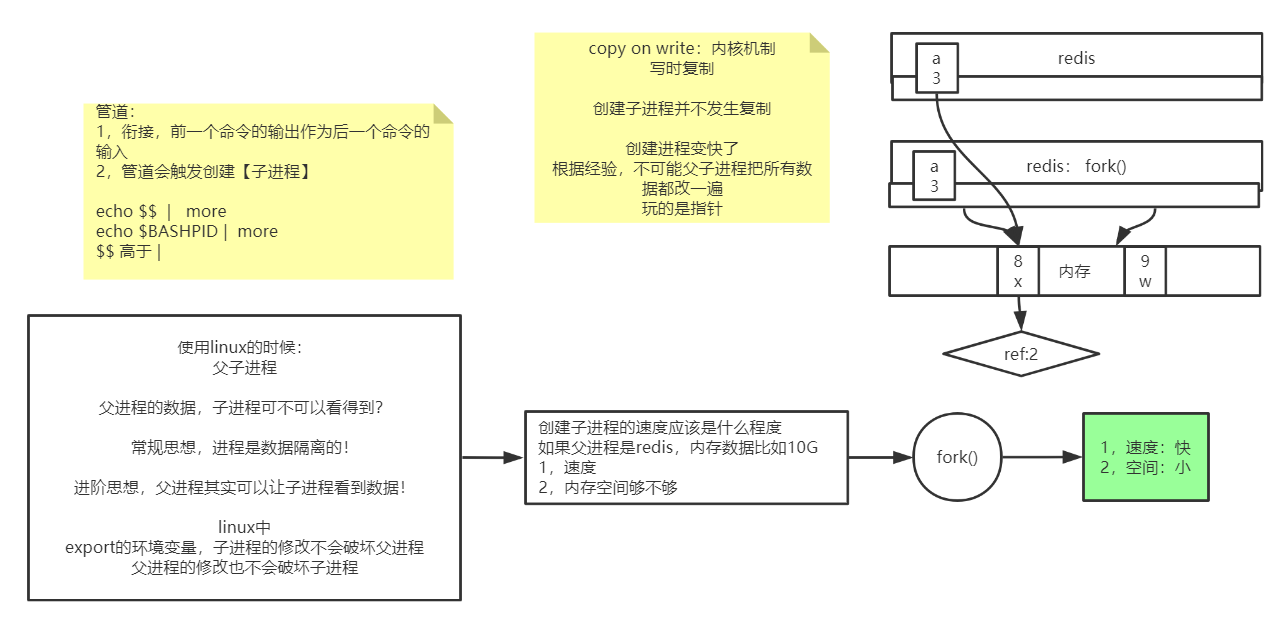
要拷贝, 就是把真实数据的地址拷贝一份到需要持久化的进程中
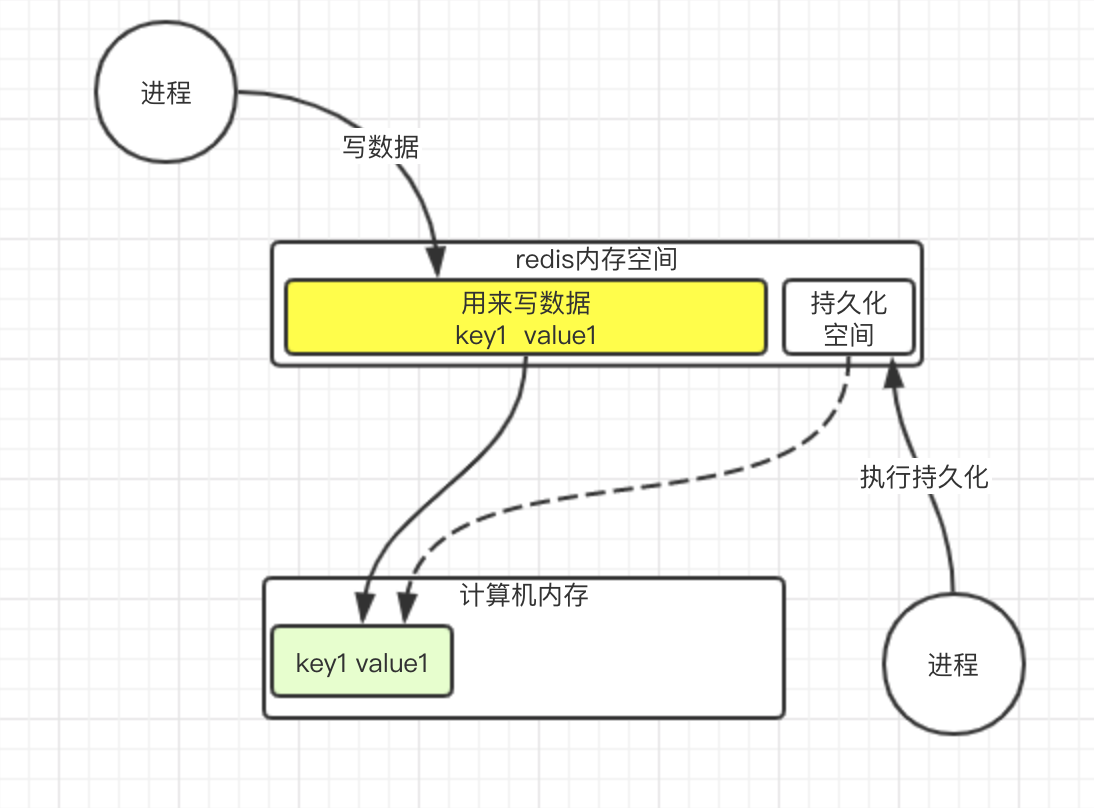
其实持久化进程这个时候只是指向了数据的地址, 内存消耗并不多. 如果这时候, 原来的数据修改了, 怎么办呢?
redis会开辟一块新的空间, 让写数据的地址指向新的空间
这样就不会影响持久化进程需要持久化的数据了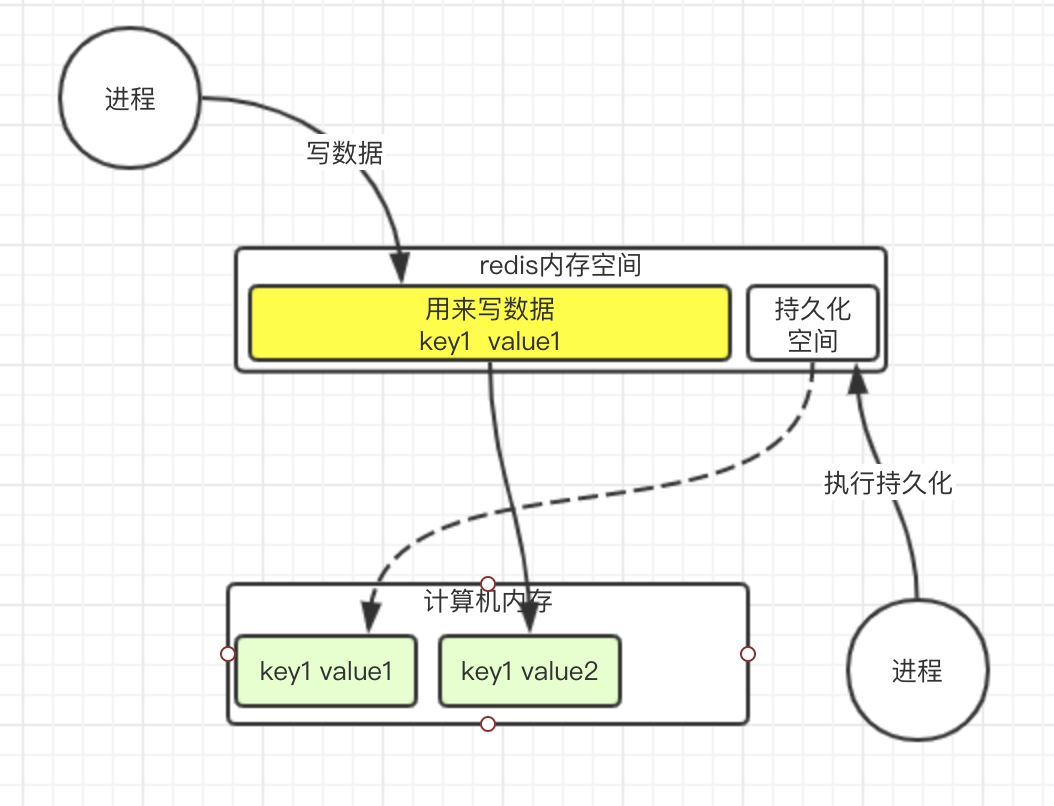
创建子进程 fork(), 实现快照
8点创建子进程, 父子进程对数据的修改, 对方看不到
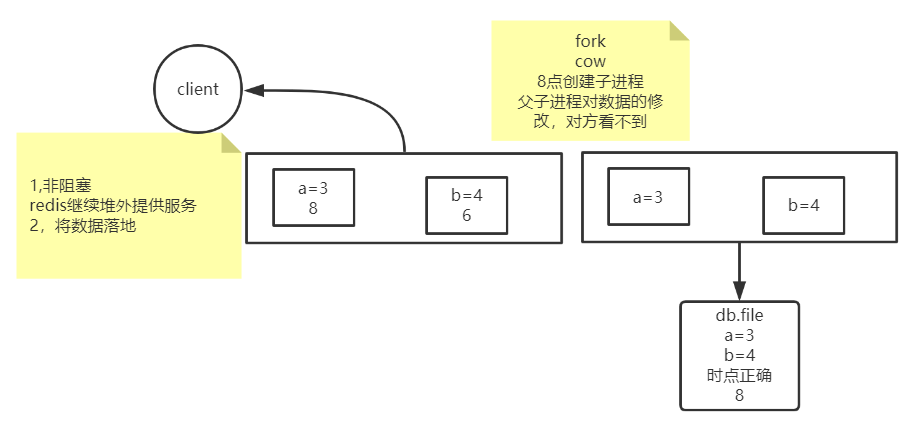
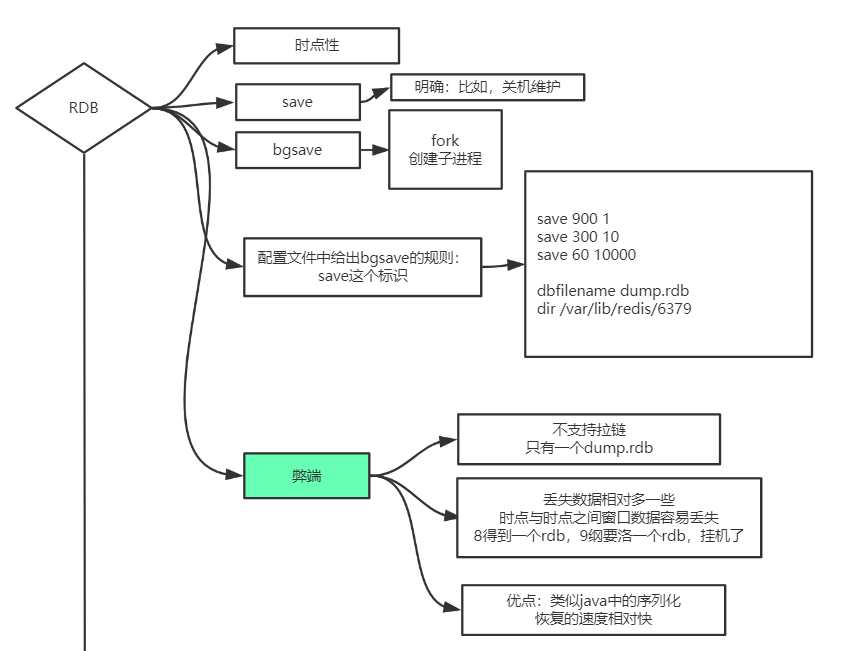
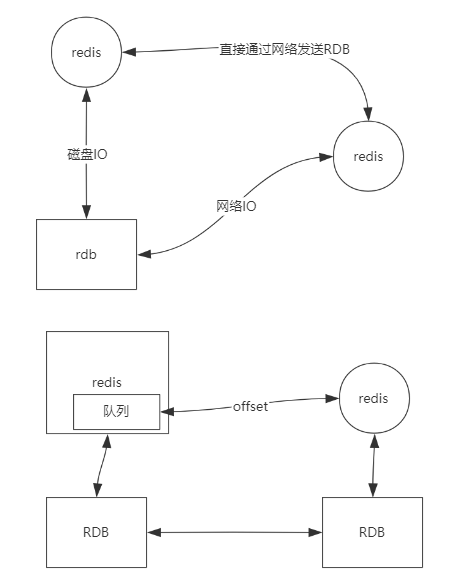
RDB实现方式
时点
save
bgsave
配置文件给出bgsave规则
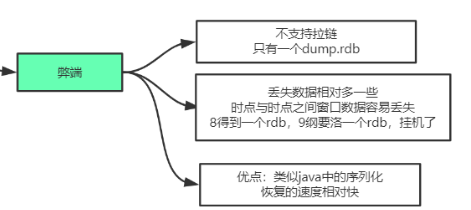
RDB优缺点
AOF
- 丢失数据少
- 4.0以后AOF是一个混合体, 重写的AOF文件的时候, Redis先用RDB写到AOF文件, 加快了重写的过程
形成混合体文件 (默认开启)
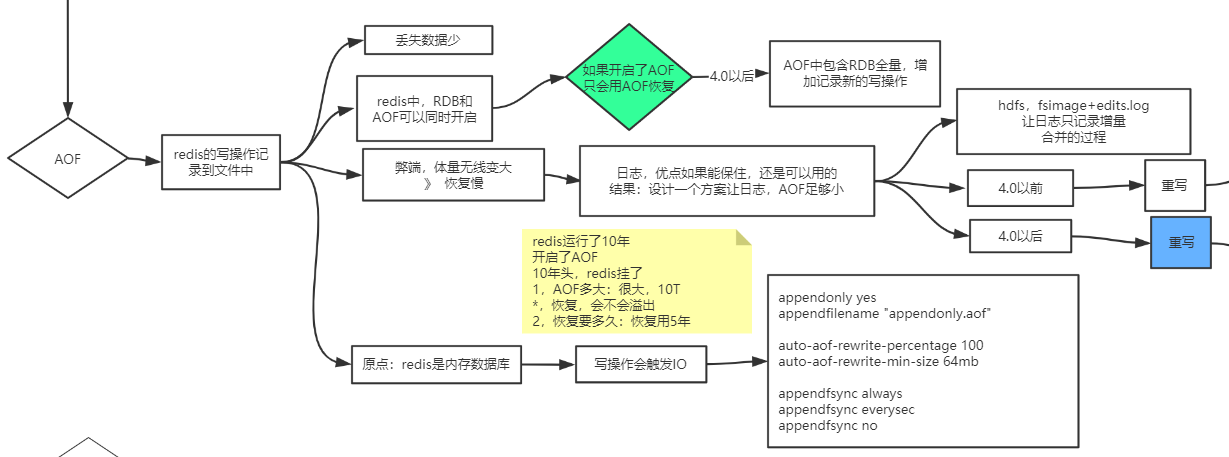
AOF日志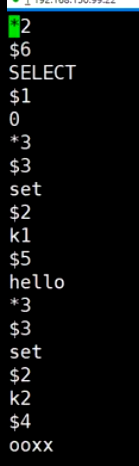
bgsave, 执行rdb

执行bgsave 生成 dump.rdb
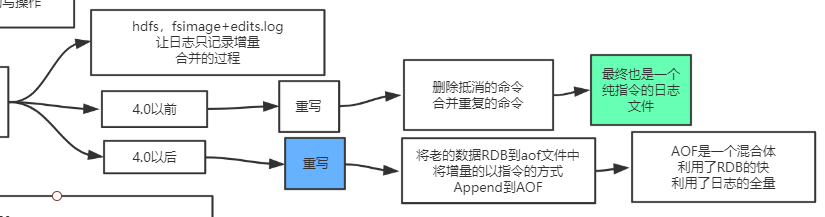
无论是混合模式还是单aof, 执行bgrewriteaof, 都只保留最后的数据, 没有历史记录
*2 有两个元素
$6 描述元素的字符数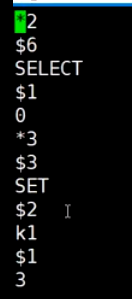
开启混合模式 aof-use-rdb-preamble yes
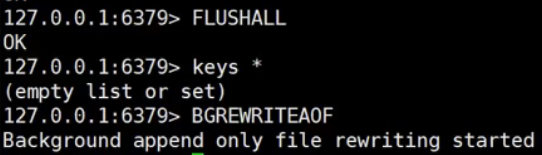
执行BGREWRITEAOF
vi appendonly.aof, 出现RDB的内容
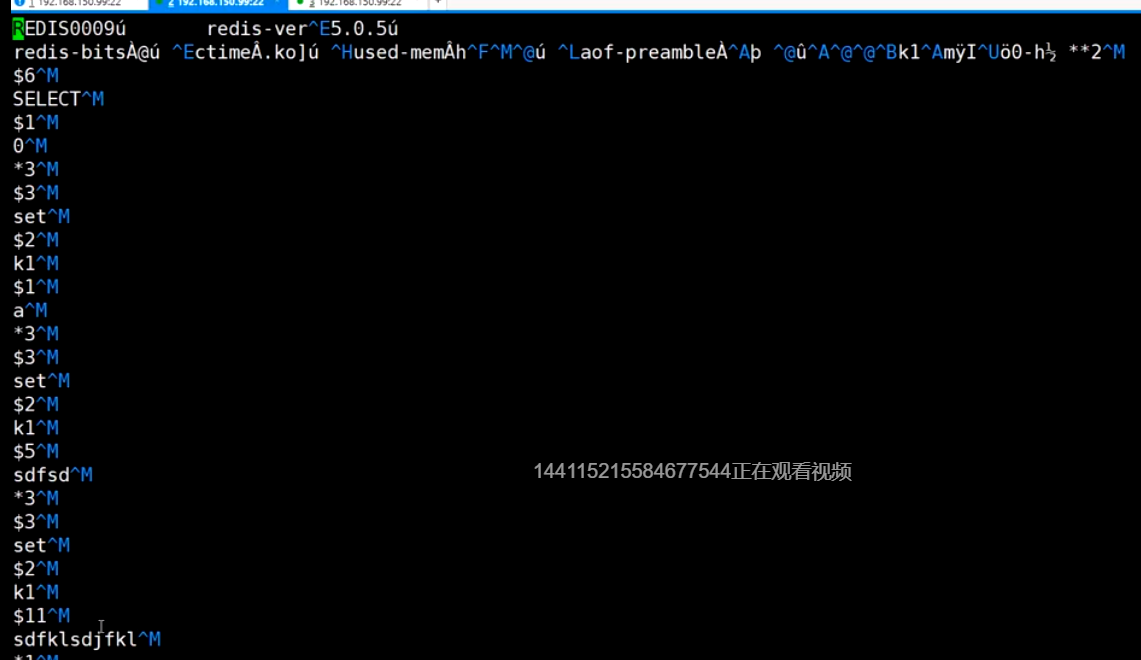
误操作后, 只要不执行BGREWRITEAOF, 可以在日志中删除误操作记录
执行BGREWRITEAOF后, 日志就会同步成当前清空的状态
开启, 修改配置文件
appendonly
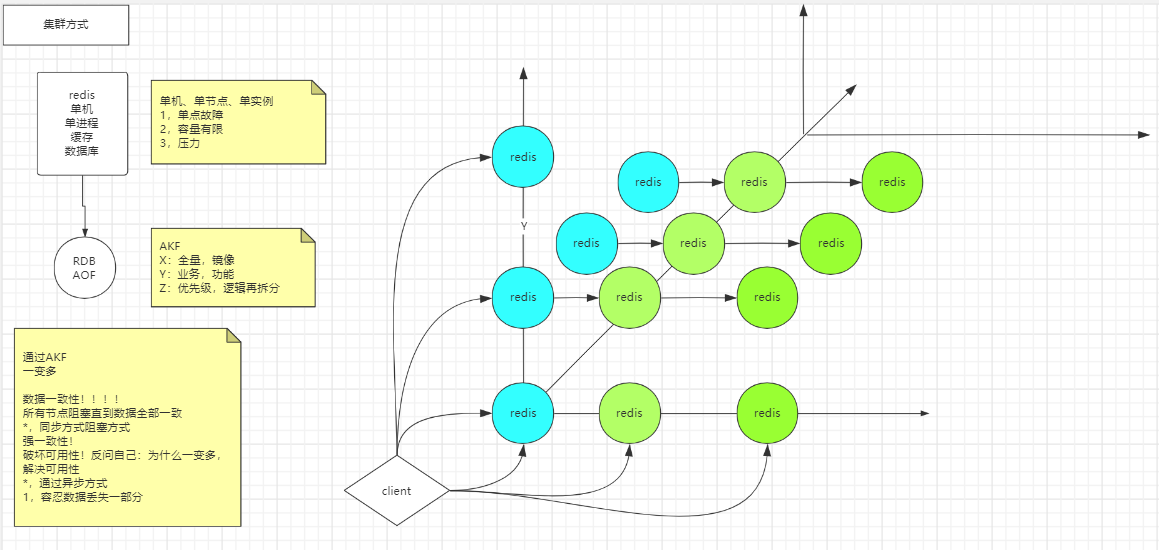
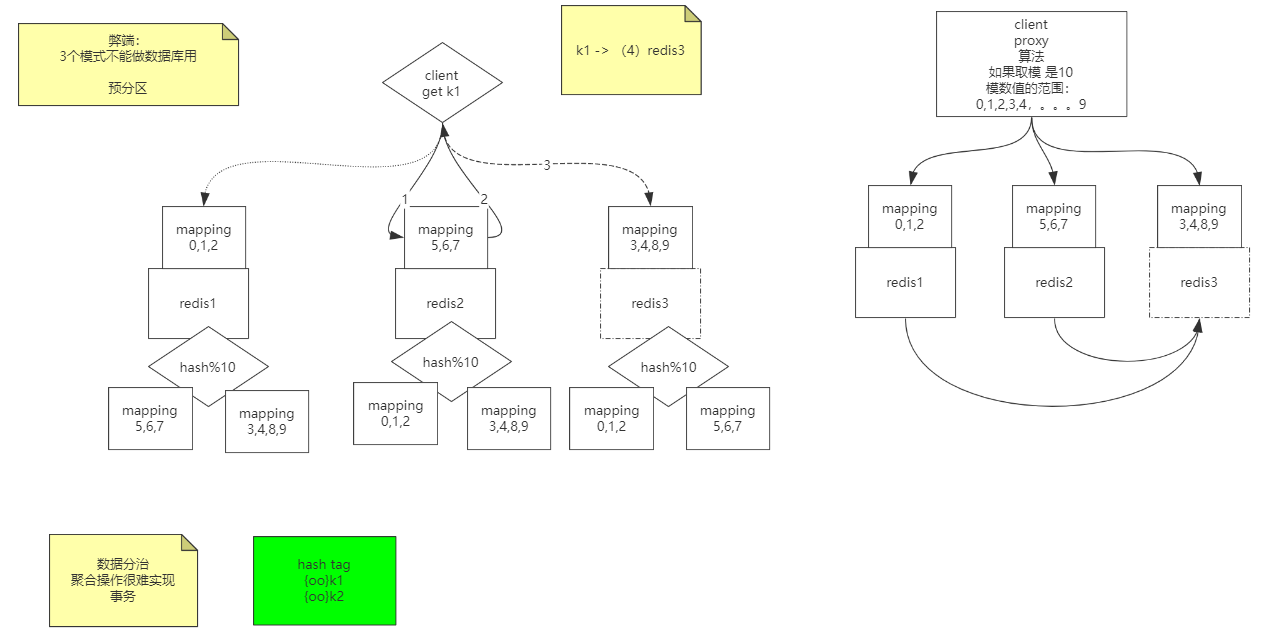
集群
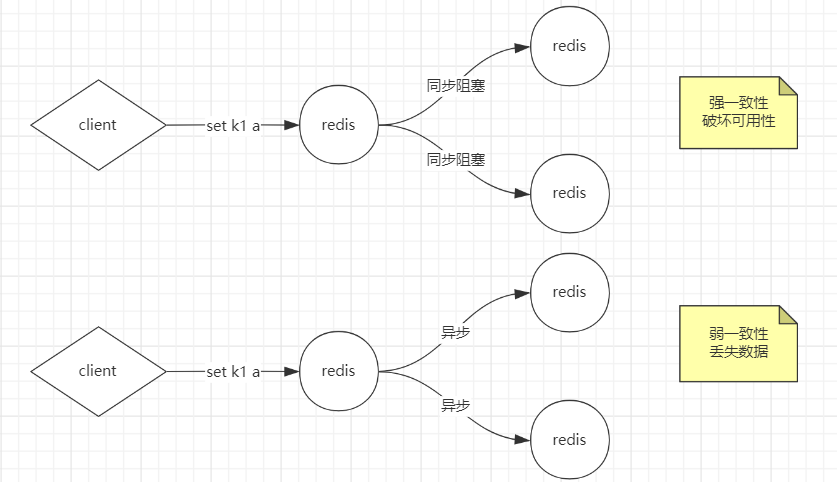
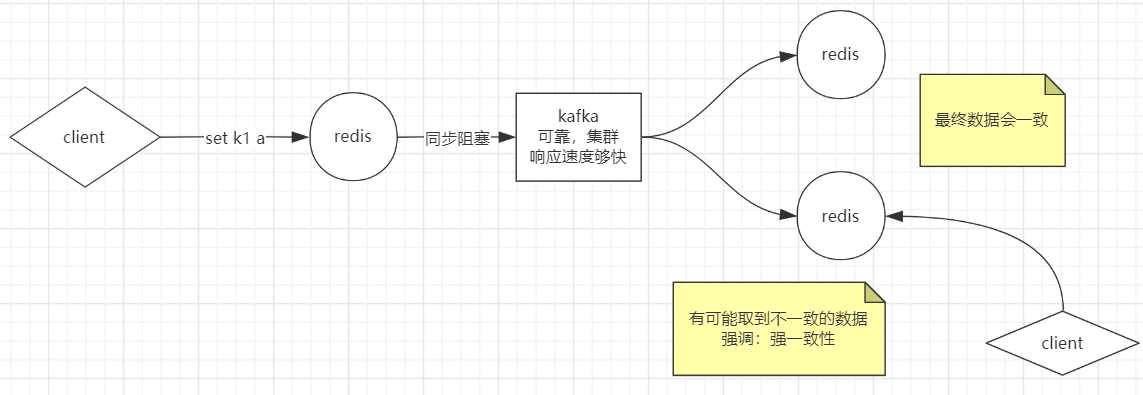


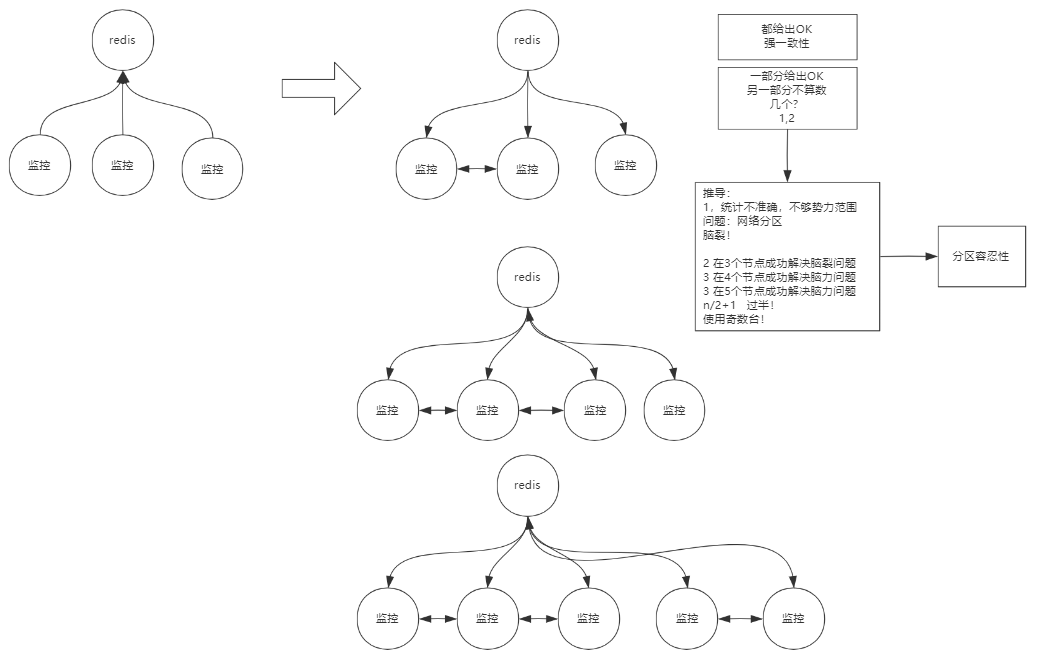
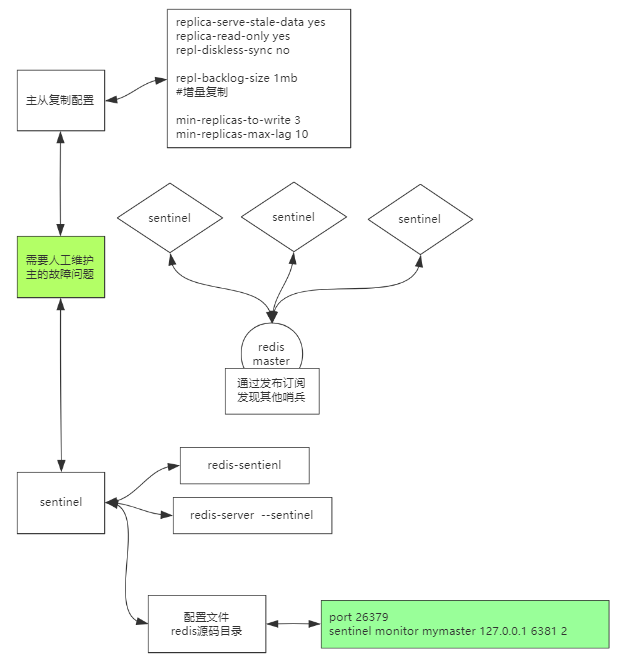
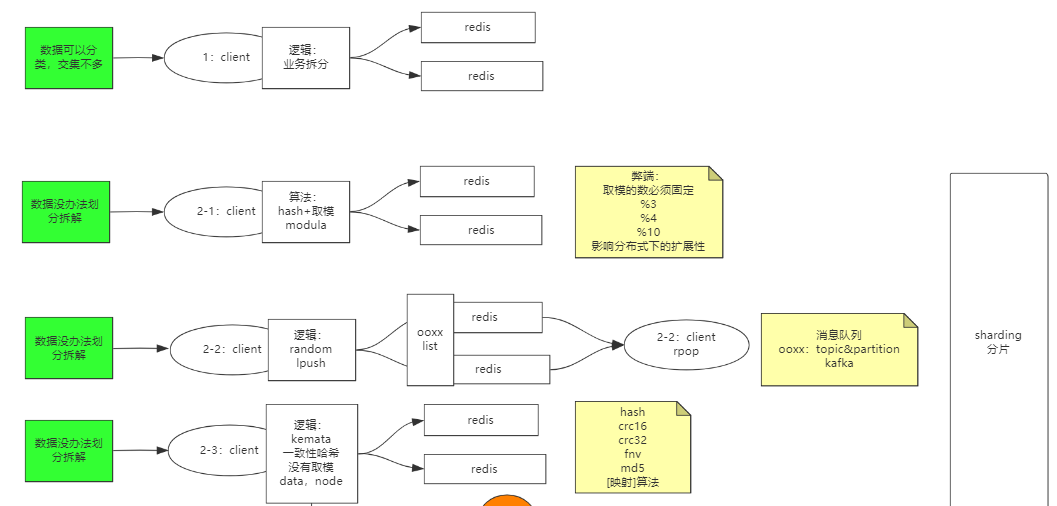
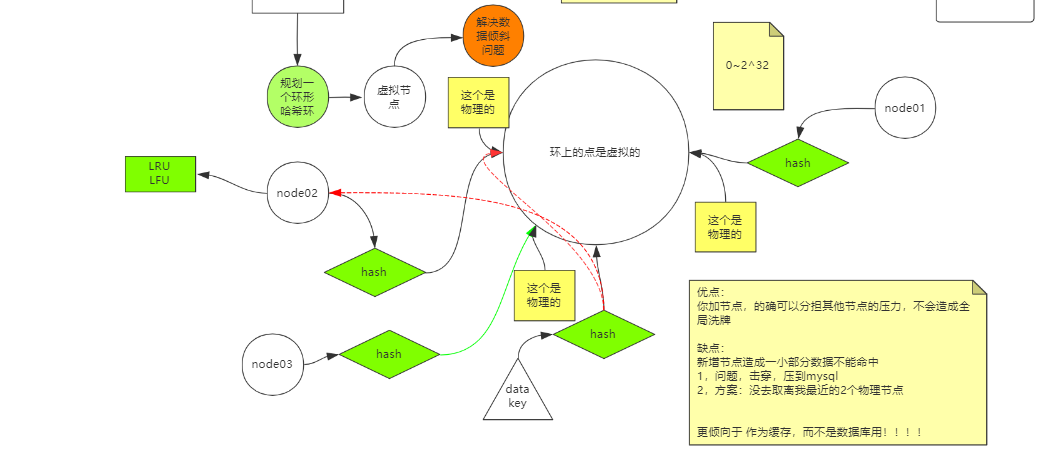
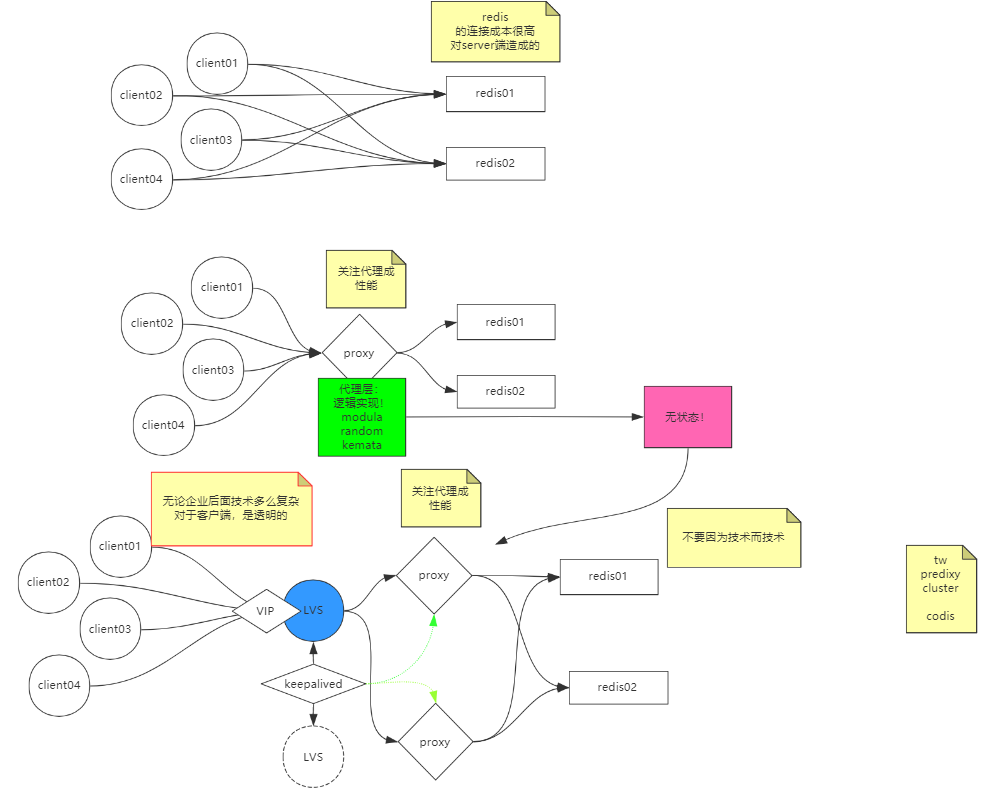
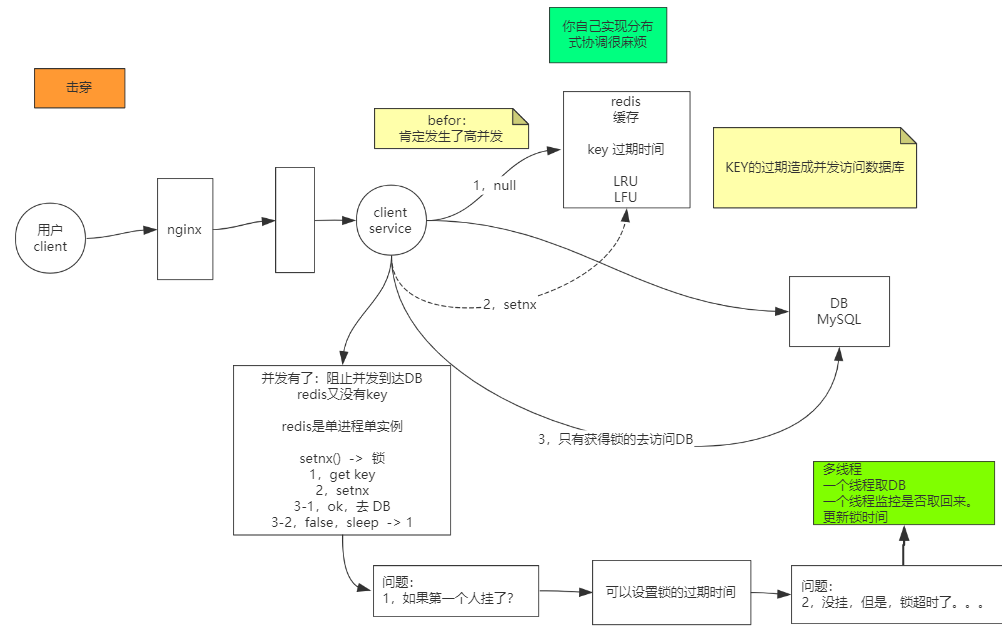
击穿
穿透
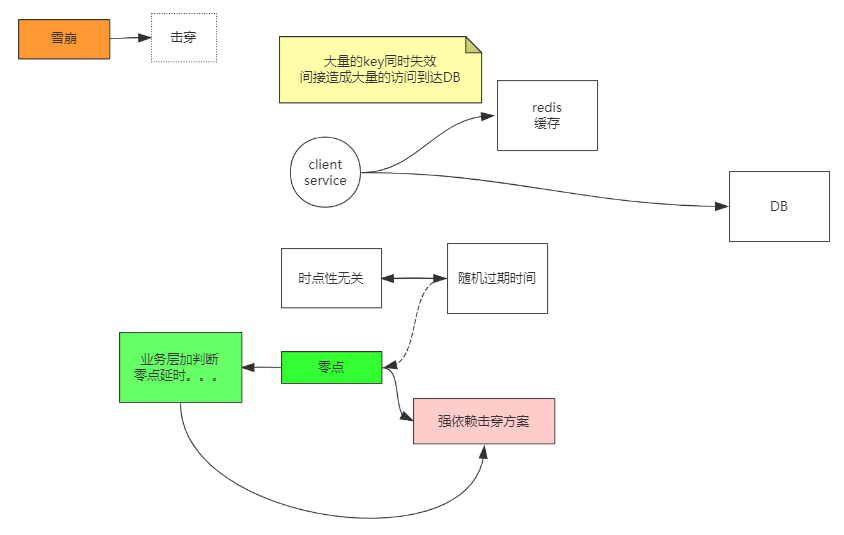
雪崩
分布式锁
基于数据库实现分布式锁;
基于缓存(Redis等)实现分布式锁;
基于Zookeeper实现分布式锁;
Memcached:利用 Memcached 的 add 命令。此命令是原子性操作,只有在 key 不存在的情况下,才能 add 成功,也就意味着线程得到了锁。
Redis:和 Memcached 的方式类似,利用 Redis 的 setnx 命令。此命令同样是原子性操作,只有在 key 不存在的情况下,才能 set 成功。
Zookeeper:利用 Zookeeper 的顺序临时节点,来实现分布式锁和等待队列。Zookeeper 设计的初衷,就是为了实现分布式锁服务的。
Chubby:Google 公司实现的粗粒度分布式锁服务,底层利用了 Paxos 一致性算法。

Spring data Redis
pom.xml
1 | <dependency> |
application.properties
1 | spring.redis.host=192.168.150.99 |
DemoApplication
1 | import org.springframework.boot.SpringApplication; |
TestRedis
1 | import com.fasterxml.jackson.databind.ObjectMapper; |
MyTemplate
1 |
|
Person
1 | public class Person { |
Redis的学习网站:
- redis.cn
- redis.io
- db-engines.com
API代码的学习:
1 | 1. redis.io 的client 中有JAVA语言的客户端:jedis、lettuce等可以分别访问他们的github学习 |