MySQL之覆盖索引、最左前缀、索引下推案例
覆盖索引
mysql的innodb引擎通过搜索树方式实现索引,索引类型分为主键索引和二级索引(非主键索引),主键索引树中,叶子结点保存着主键即对应行的全部数据;而二级索引树中,叶子结点保存着索引值和主键值,当使用二级索引进行查询时,需要进行回表操作。假如我们现在有如下表结构
1 | CREATE TABLE `user_table` ( |
执行语句(A) select id from user_table where username = ‘lzs’时,因为username索引树的叶子结点上保存有username和id的值,所以通过username索引树查找到id后,我们就已经得到所需的数据了,这时候就不需要再去主键索引上继续查找了。
执行语句(B) select password from user_table where username = ‘lzs’时,流程如下
1、username索引树上找到username=lzs对应的主键id
2、通过回表在主键索引树上找到满足条件的数据
由上面可知,当sql语句的所求查询字段(select列)和查询条件字段(where子句)全都包含在一个索引中,可以直接使用索引查询而不需要回表。这就是覆盖索引,通过使用覆盖索引,可以减少搜索树的次数,是常用的性能优化手段。
例如上面的语句B是一个高频查询的语句,我们可以建立(username,password)的联合索引,这样,查询的时候就不需要再去回表操作了,可以提高查询效率。当然,添加索引是有维护代价的,所以添加时也要权衡一下。
联合索引
mysql的b+树索引遵循“最左前缀”原则,继续以上面的例子来说明,为了提高语句B的执行速度,我们添加了一个联合索引(username,password),特别注意这个联合索引的顺序,如果我们颠倒下顺序改成(password,username),这样查询能使用这个索引吗?答案是不能的!这是最左前缀的第一层含义:联合索引的多个字段中,只有当查询条件为联合索引的一个字段时,查询才能使用该索引。
现在,假设我们有一下三种查询情景:
1、查出用户名的第一个字是“张”开头的人的密码。即查询条件子句为”where username like ‘张%’”
2、查处用户名中含有“张”字的人的密码。即查询条件子句为”where username like ‘%张%’”
3、查出用户名以“张”字结尾的人的密码。即查询条件子句为”where username like ‘%张’”
以上三种情况下,只有第1种能够使用(username,password)联合索引来加快查询速度。这就是最左前缀的第二层含义:索引可以用于查询条件字段为索引字段,根据字段值最左若干个字符进行的模糊查询。
维护索引需要代价,所以有时候我们可以利用“最左前缀”原则减少索引数量,上面的(username,password)索引,也可用于根据username查询age的情况。当然,使用这个索引去查询age的时候是需要进行回表的,当这个需求(根据username查询age)也是高频请求时,我们可以创建(username,password,age)联合索引,这样,我们需要维护的索引数量不变。
创建索引时,我们也要考虑空间代价,使用较少的空间来创建索引
假设我们现在不需要通过username查询password了,相反,经常需要通过username查询age或通过age查询username,这时候,删掉(username,password)索引后,我们需要创建新的索引,我们有两种选择
1、(username,age)联合索引+age字段索引
2、(age,username)联合索引+username单字段索引
一般来说,username字段比age字段大的多,所以,我们应选择第一种,索引占用空间较小。
索引下推
对于user_table表,我们现在有(username,age)联合索引
如果现在有一个需求,查出名称中以“张”开头且年龄小于等于10的用户信息,语句C如下:”select * from user_table where username like ‘张%’ and age > 10”.
语句C有两种执行可能:
1、根据(username,age)联合索引查询所有满足名称以“张”开头的索引,然后回表查询出相应的全行数据,然后再筛选出满足年龄小于等于10的用户数据。过程如下图。
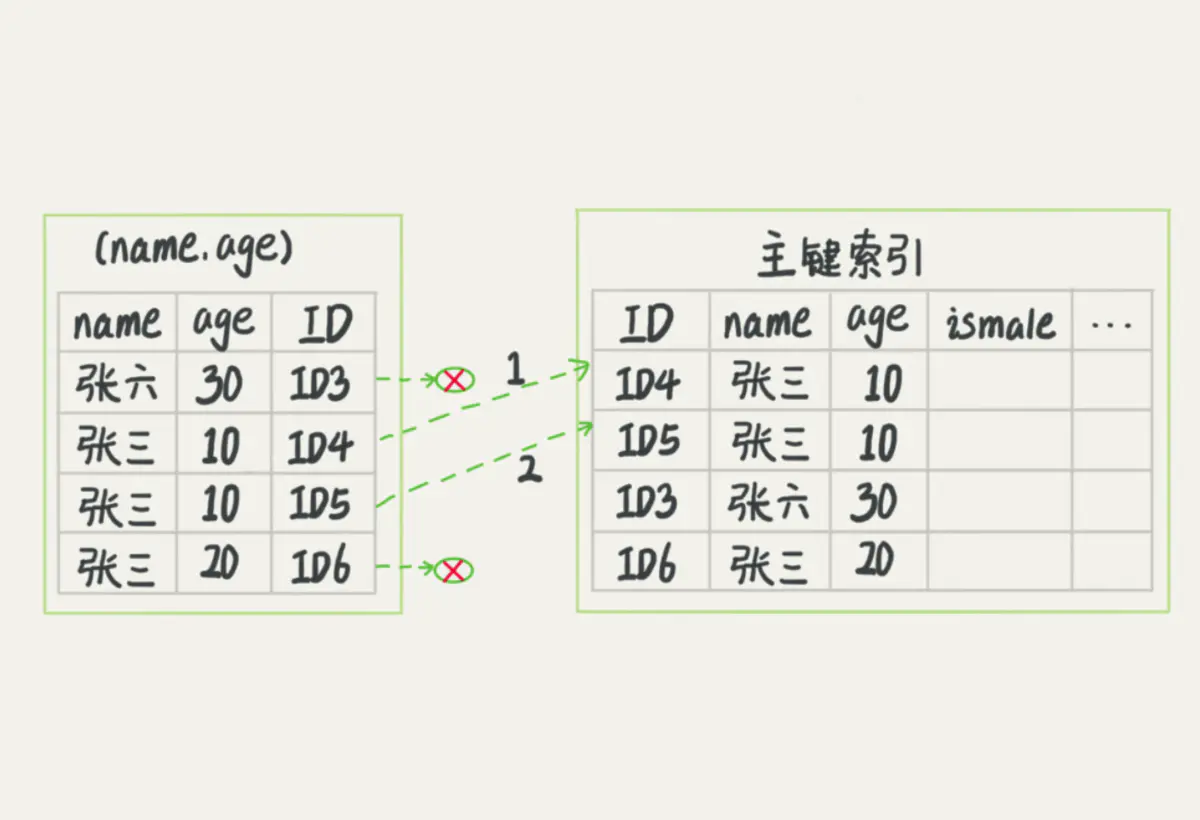
2、根据(username,age)联合索引查询所有满足名称以“张”开头的索引,然后直接再筛选出年龄小于等于10的索引,之后再回表查询全行数据。过程如下图。
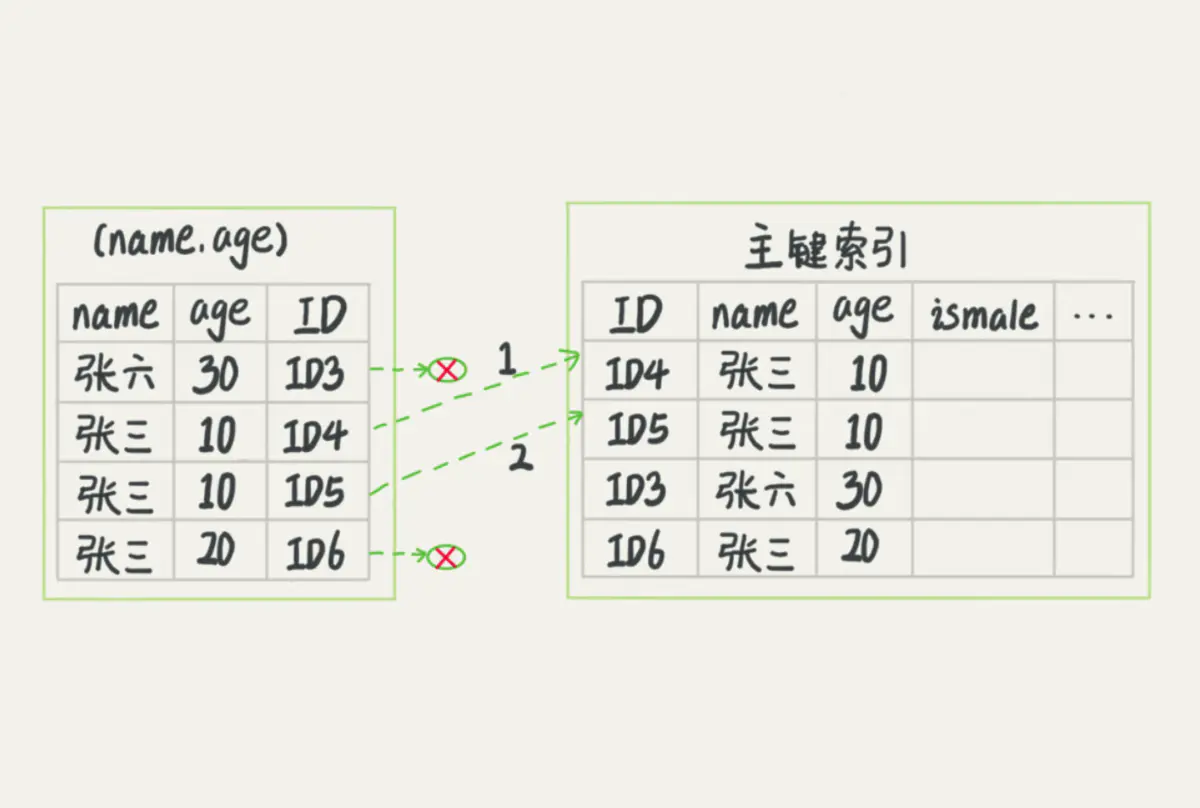
明显的,第二种方式需要回表查询的全行数据比较少,这就是mysql的索引下推。mysql默认启用索引下推,我们也可以通过修改系统变量optimizer_switch的index_condition_pushdown标志来控制
1 | SET optimizer_switch = 'index_condition_pushdown=off'; |
注意点:
1、innodb引擎的表,索引下推只能用于二级索引。就像之前提到的,innodb的主键索引树叶子结点上保存的是全行数据,所以这个时候索引下推并不会起到减少查询全行数据的效果。
2、索引下推一般可用于所求查询字段(select列)不是/不全是联合索引的字段,查询条件为多条件查询且查询条件子句(where/order by)字段全是联合索引。
假设表t有联合索引(a,b),下面语句可以使用索引下推提高效率
select * from t where a > 2 and b > 10;