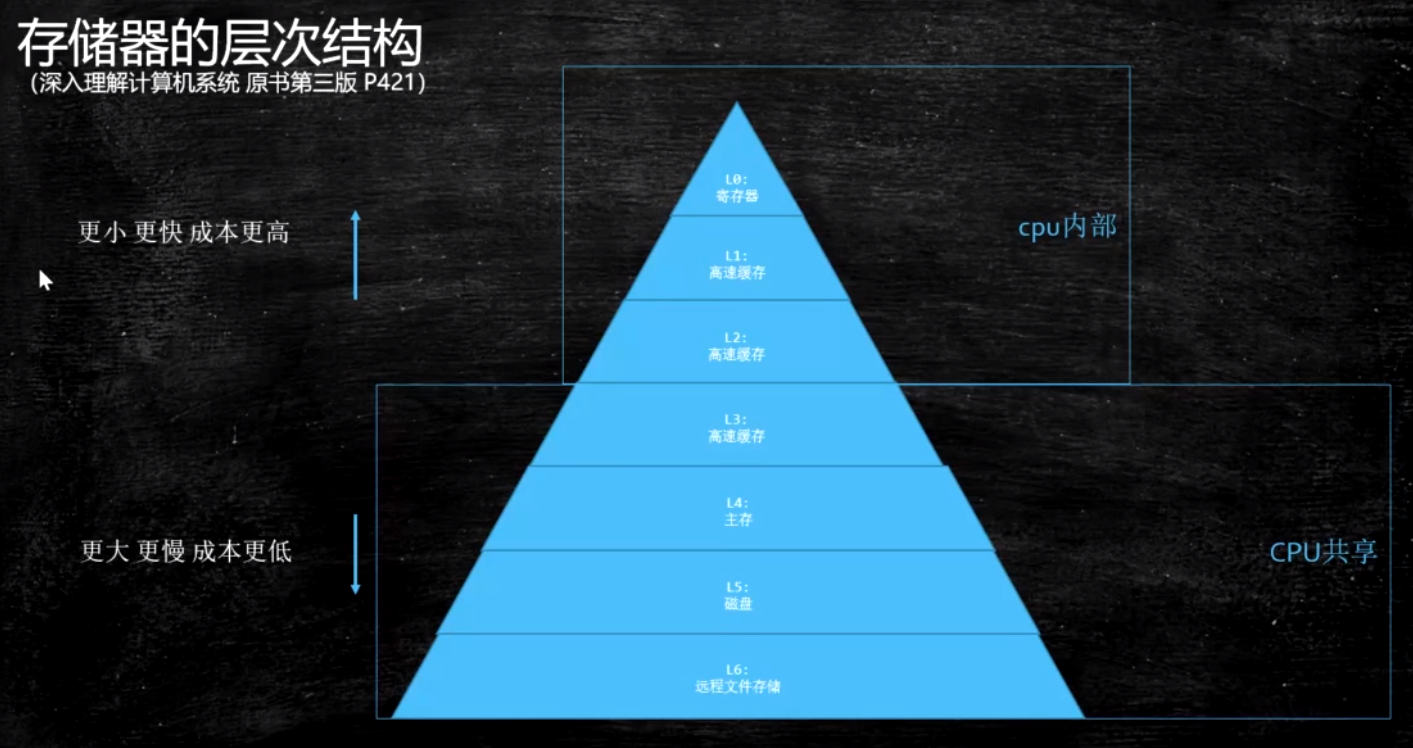
离CPU越近, 速度越快, 空间越小

数据不一致问题


缓存锁
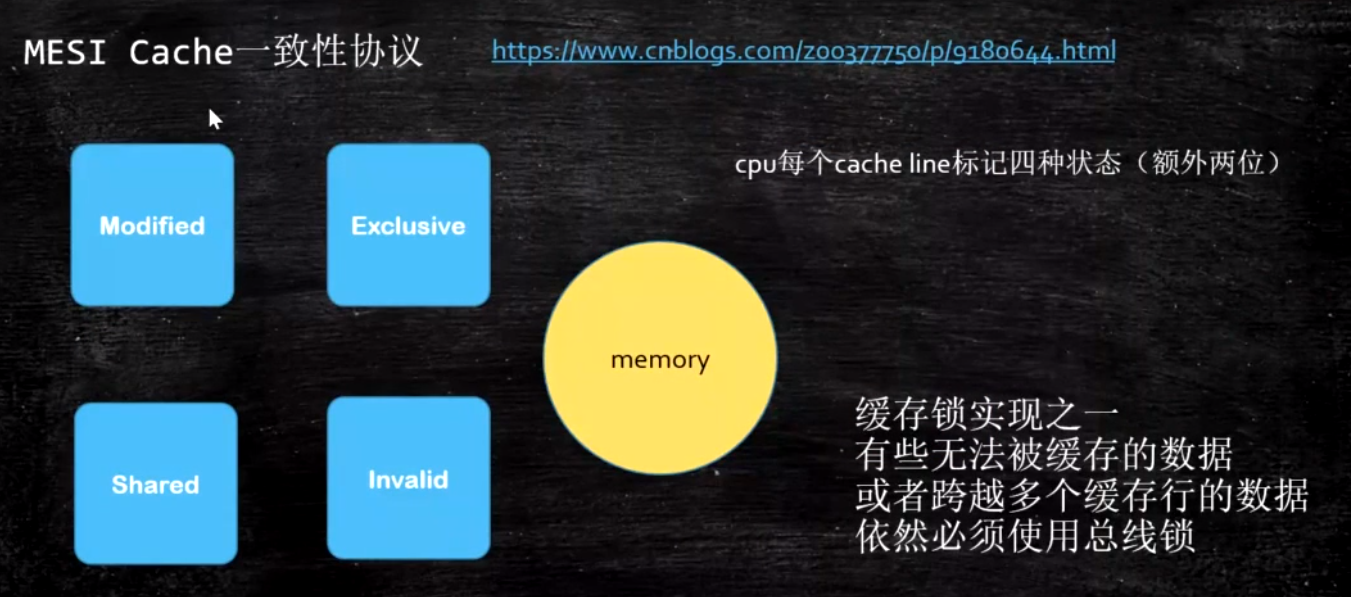
和主存内容比较
Modified改过, 再加载 Exclusive独享 Shared我读的时候别人也在读 Invalid读时被别的CPU改过
现代CPU的数据一致性实现 = 缓存锁(MESI …) + 总线锁读取缓存以cache line为基本单位,目前64bytes
位于同一缓存行的两个不同数据,被两个不同CPU锁定,产生互相影响的伪共享问题
伪共享问题:JUC/c_028_FalseSharing
使用缓存行的对齐能够提高效率

乱序问题
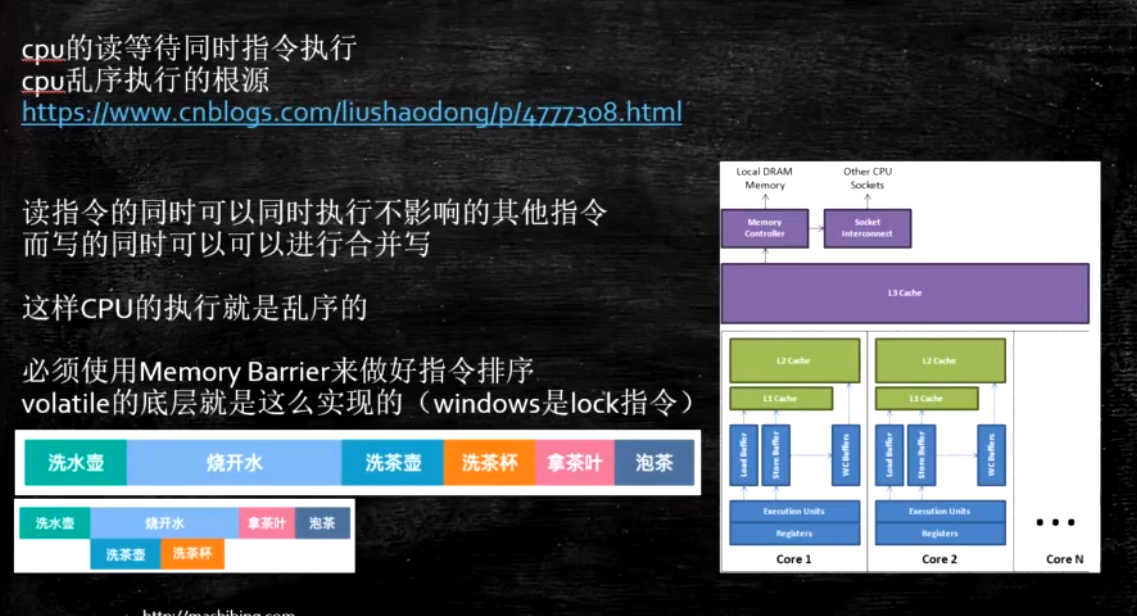
CPU为了提高指令执行效率,会在一条指令执行过程中(比如去内存读数据(慢100倍)),去同时执行另一条指令,前提是,两条指令没有依赖关系
写操作也可以进行合并
乱序执行的证明:JVM/jmm/Disorder.java
如何保证特定情况下不乱序
硬件内存屏障 X86
sfence: store| 在sfence指令前的写操作当必须在sfence指令后的写操作前完成。
lfence:load | 在lfence指令前的读操作当必须在lfence指令后的读操作前完成。
mfence:modify/mix | 在mfence指令前的读写操作当必须在mfence指令后的读写操作前完成。
原子指令,如x86上的”lock …” 指令是一个Full Barrier,执行时会锁住内存子系统来确保执行顺序,甚至跨多个CPU。Software Locks通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序
JVM级别如何规范(JSR133)
LoadLoad屏障:
对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。StoreStore屏障:
对于这样的语句Store1; StoreStore; Store2, 在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。LoadStore屏障:
对于这样的语句Load1; LoadStore; Store2, 在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。StoreLoad屏障:
对于这样的语句Store1; StoreLoad; Load2, 在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。
volatile的实现细节
字节码层面
ACC_VOLATILEJVM层面
volatile内存区的读写 都加屏障StoreStoreBarrier
volatile 写操作
StoreLoadBarrier
LoadLoadBarrier
volatile 读操作
LoadStoreBarrier

OS和硬件层面
https://blog.csdn.net/qq_26222859/article/details/52235930
hsdis - HotSpot Dis Assembler
windows lock 指令实现 | MESI实现
synchronized实现细节
- 字节码层面
ACC_SYNCHRONIZED
monitorenter monitorexit - JVM层面
C C++ 调用了操作系统提供的同步机制 - OS和硬件层面
X86 : lock cmpxchg / xxx
https://blog.csdn.net/21aspnet/article/details/[88571740


观察虚拟机配置
java -XX:+PrintCommandLineFlags -version
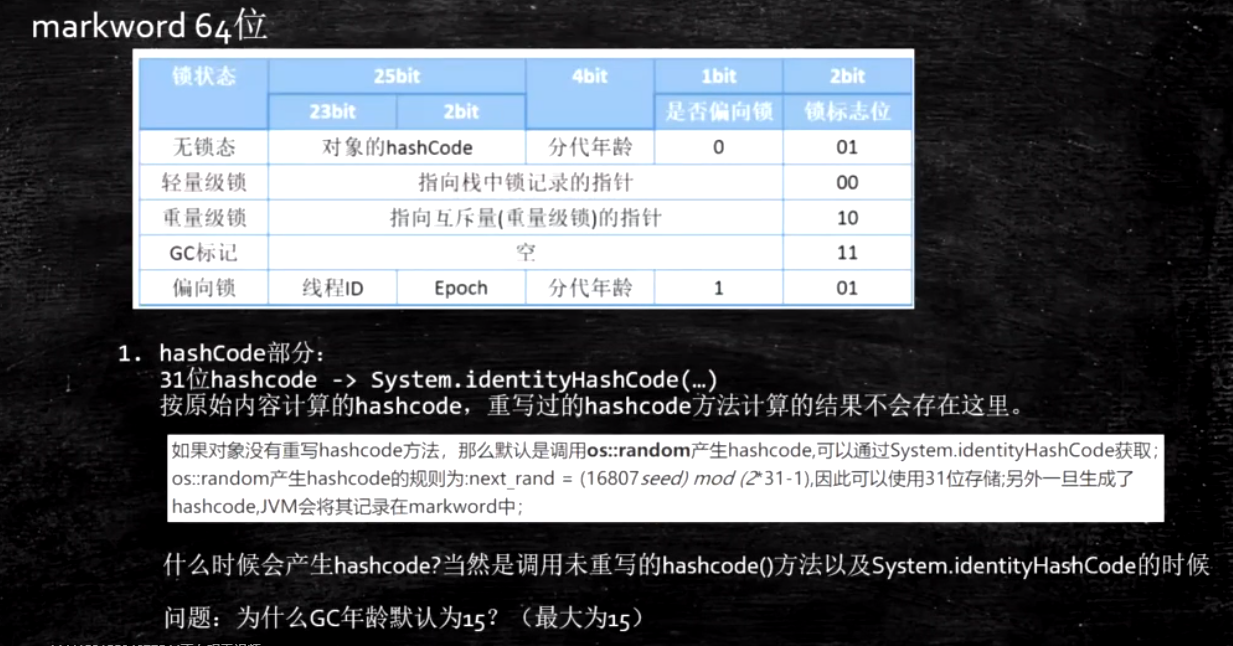
普通对象

- 对象头:markword 8
- ClassPointer指针:-XX:+UseCompressedClassPointers 为4字节 不开启为8字节
- 实例数据
- 引用类型:-XX:+UseCompressedOops 为4字节 不开启为8字节
Oops Ordinary Object Pointers
- 引用类型:-XX:+UseCompressedOops 为4字节 不开启为8字节
- Padding对齐,8的倍数
数组对象
- 对象头:markword 8
- ClassPointer指针同上
- 数组长度:4字节
- 数组数据
- 对齐 8的倍数

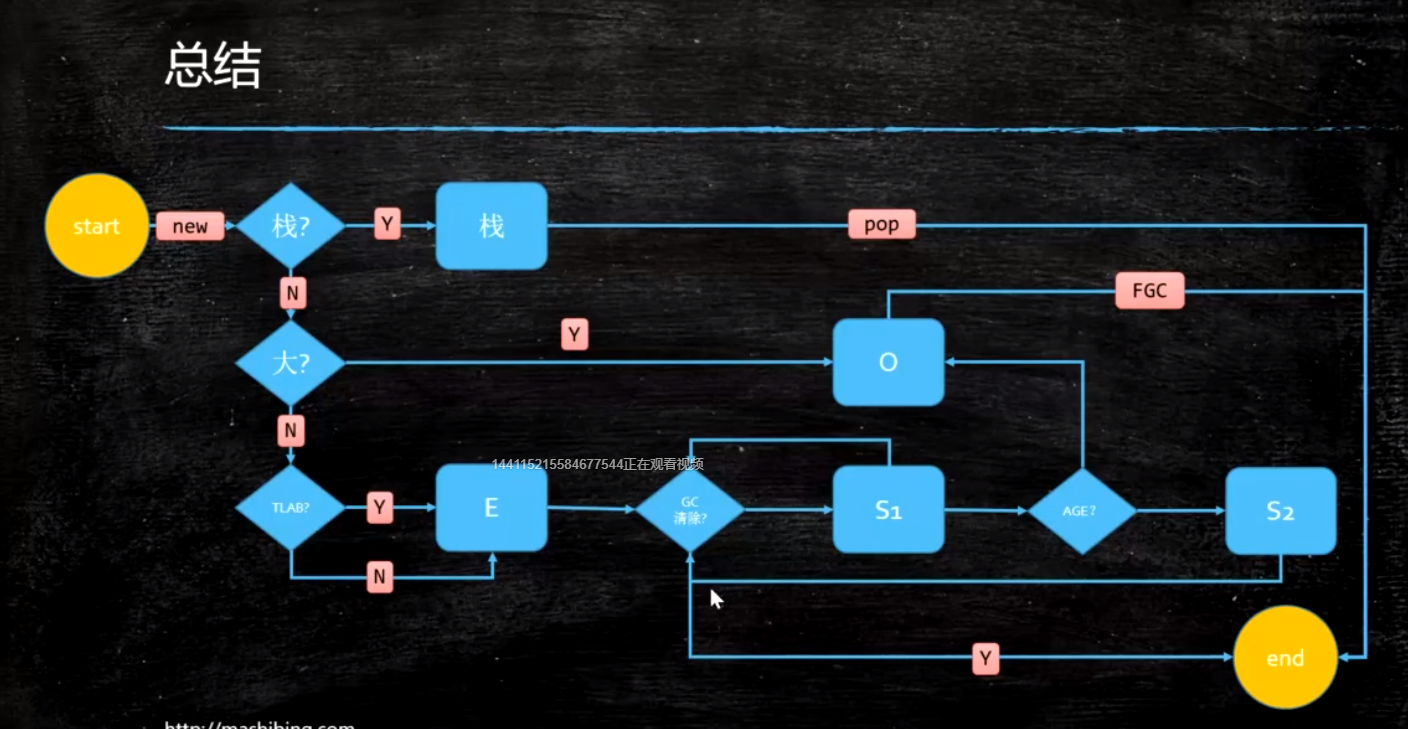



Heap
Method Area
- Perm Space (<1.8)
字符串常量位于PermSpace
FGC不会清理
大小启动的时候指定,不能变 - Meta Space (>=1.8)
字符串常量位于堆
会触发FGC清理
不设定的话,最大就是物理内存
Runtime Constant Pool
Native Method Stack
Direct Memory
JVM可以直接访问的内核空间的内存 (OS 管理的内存)
NIO , 提高效率,实现zero copy
思考:
如何证明1.7字符串常量位于Perm,而1.8位于Heap?
提示:结合GC, 一直创建字符串常量,观察堆,和Metaspace
PC 程序计数器
存放指令位置
虚拟机的运行,类似于这样的循环:
while( not end ) {
取PC中的位置,找到对应位置的指令;
执行该指令;
PC ++;
}







局部变量+操作数栈+
JVM Stack
- Frame - 每个方法对应一个栈帧
- Local Variable Table
- Operand Stack
对于long的处理(store and load),多数虚拟机的实现都是原子的
jls 17.7,没必要加volatile - Dynamic Linking
https://blog.csdn.net/qq_41813060/article/details/88379473
jvms 2.6.3 - return address
a() -> b(),方法a调用了方法b, b方法的返回值放在什么地方
int i = 8;
i++;
sout(i)

(右 i = i++) 相当于先把值放在内存, 再赋值给寄存器中
1: 先把8压栈,
2: 把8弹到局部变量表为1的位置 (完成int i = 8)
3: 把局部变量表为1位置上的8压栈 (用到 i)
4: 把局部变量表为1位置上的数+1 (完成 i++)
5: 把8弹到局部变量表为1的位置 (完成 i = i++)
i = ++i : 先+1再压栈



一个方法对应一个栈针
非静态方法, 第0个位置是this

3,4已经出栈, 7压栈, load压栈, store弹栈

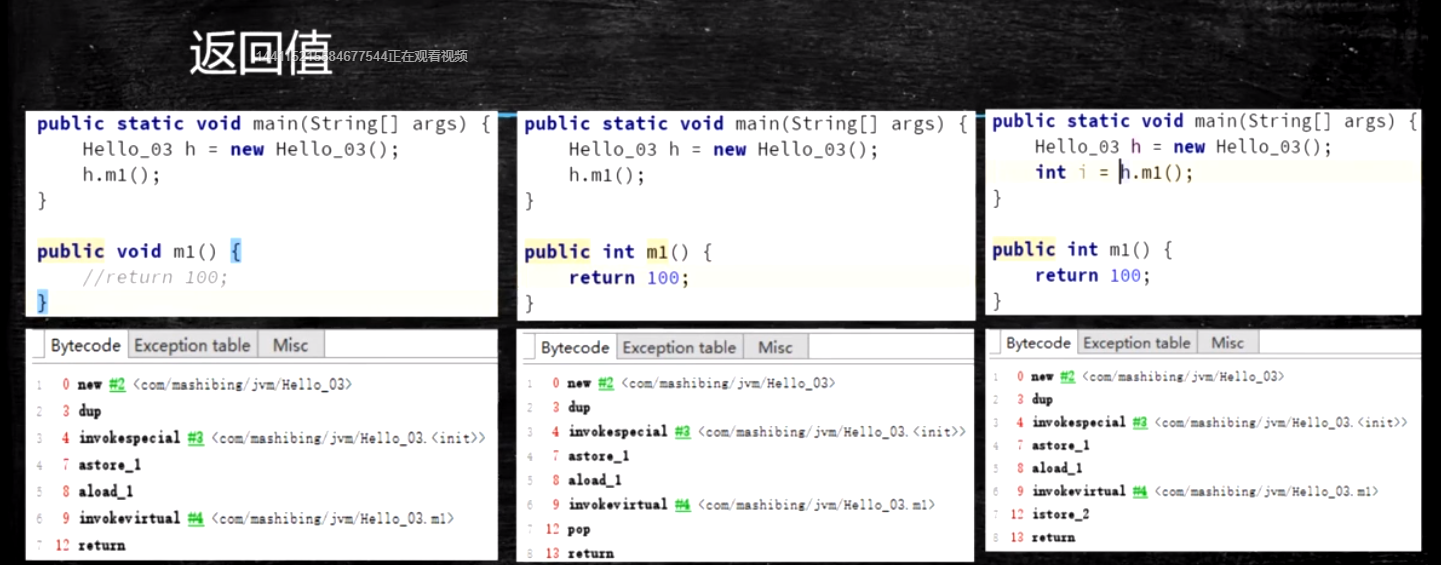
第二个: 100放在main方法栈顶, 直接弹出, 结束
第三个: 100弹到局部变量表2位置(args是0,h是1, i是2), 结束
递归调用: 三个栈

常用指令
store
load
pop
mul
sub
invoke
- InvokeStatic
- InvokeVirtual
- InvokeInterface
- InovkeSpecial
可以直接定位,不需要多态的方法
private 方法 , 构造方法 - InvokeDynamic
JVM最难的指令
lambda表达式或者反射或者其他动态语言scala kotlin,或者CGLib ASM,动态产生的class,会用到的指令
JMM
硬件层数据一致性
协议很多
intel 用MESI
https://www.cnblogs.com/z00377750/p/9180644.html
现代CPU的数据一致性实现 = 缓存锁(MESI …) + 总线锁
读取缓存以cache line为基本单位,目前64bytes
位于同一缓存行的两个不同数据,被两个不同CPU锁定,产生互相影响的伪共享问题
伪共享问题:JUC/c_028_FalseSharing
使用缓存行的对齐能够提高效率
乱序问题
CPU为了提高指令执行效率,会在一条指令执行过程中(比如去内存读数据(慢100倍)),去同时执行另一条指令,前提是,两条指令没有依赖关系
https://www.cnblogs.com/liushaodong/p/4777308.html
写操作也可以进行合并
https://www.cnblogs.com/liushaodong/p/4777308.html
JUC/029_WriteCombining
乱序执行的证明:JVM/jmm/Disorder.java
原始参考:https://preshing.com/20120515/memory-reordering-caught-in-the-act/
如何保证特定情况下不乱序
硬件内存屏障 X86
sfence: store| 在sfence指令前的写操作当必须在sfence指令后的写操作前完成。
lfence:load | 在lfence指令前的读操作当必须在lfence指令后的读操作前完成。
mfence:modify/mix | 在mfence指令前的读写操作当必须在mfence指令后的读写操作前完成。
原子指令,如x86上的”lock …” 指令是一个Full Barrier,执行时会锁住内存子系统来确保执行顺序,甚至跨多个CPU。Software Locks通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序
JVM级别如何规范(JSR133)
LoadLoad屏障:
对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。StoreStore屏障:
对于这样的语句Store1; StoreStore; Store2, 在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。LoadStore屏障:
对于这样的语句Load1; LoadStore; Store2, 在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。StoreLoad屏障:
对于这样的语句Store1; StoreLoad; Load2, 在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。
volatile的实现细节
字节码层面
ACC_VOLATILEJVM层面
volatile内存区的读写 都加屏障StoreStoreBarrier
volatile 写操作
StoreLoadBarrier
LoadLoadBarrier
volatile 读操作
LoadStoreBarrier
OS和硬件层面
https://blog.csdn.net/qq_26222859/article/details/52235930
hsdis - HotSpot Dis Assembler
windows lock 指令实现 | MESI实现
synchronized实现细节
- 字节码层面
ACC_SYNCHRONIZED
monitorenter monitorexit - JVM层面
C C++ 调用了操作系统提供的同步机制 - OS和硬件层面
X86 : lock cmpxchg / xxx
https://blog.csdn.net/21aspnet/article/details/88571740
使用JavaAgent测试Object的大小
作者:马士兵 http://www.mashibing.com
对象大小(64位机)
观察虚拟机配置
java -XX:+PrintCommandLineFlags -version
普通对象
- 对象头:markword 8
- ClassPointer指针:-XX:+UseCompressedClassPointers 为4字节 不开启为8字节
- 实例数据
- 引用类型:-XX:+UseCompressedOops 为4字节 不开启为8字节
Oops Ordinary Object Pointers
- 引用类型:-XX:+UseCompressedOops 为4字节 不开启为8字节
- Padding对齐,8的倍数
数组对象
- 对象头:markword 8
- ClassPointer指针同上
- 数组长度:4字节
- 数组数据
- 对齐 8的倍数
实验
新建项目ObjectSize (1.8)
创建文件ObjectSizeAgent
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15package com.mashibing.jvm.agent;
import java.lang.instrument.Instrumentation;
public class ObjectSizeAgent {
private static Instrumentation inst;
public static void premain(String agentArgs, Instrumentation _inst) {
inst = _inst;
}
public static long sizeOf(Object o) {
return inst.getObjectSize(o);
}
}src目录下创建META-INF/MANIFEST.MF
1
2
3Manifest-Version: 1.0
Created-By: mashibing.com
Premain-Class: com.mashibing.jvm.agent.ObjectSizeAgent注意Premain-Class这行必须是新的一行(回车 + 换行),确认idea不能有任何错误提示
打包jar文件
在需要使用该Agent Jar的项目中引入该Jar包
project structure - project settings - library 添加该jar包运行时需要该Agent Jar的类,加入参数:
1
-javaagent:C:\work\ijprojects\ObjectSize\out\artifacts\ObjectSize_jar\ObjectSize.jar
如何使用该类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27```java
package com.mashibing.jvm.c3_jmm;
import com.mashibing.jvm.agent.ObjectSizeAgent;
public class T03_SizeOfAnObject {
public static void main(String[] args) {
System.out.println(ObjectSizeAgent.sizeOf(new Object()));
System.out.println(ObjectSizeAgent.sizeOf(new int[] {}));
System.out.println(ObjectSizeAgent.sizeOf(new P()));
}
private static class P {
//8 _markword
//4 _oop指针
int id; //4
String name; //4
int age; //4
byte b1; //1
byte b2; //1
Object o; //4
byte b3; //1
}
}
Hotspot开启内存压缩的规则(64位机)
- 4G以下,直接砍掉高32位
- 4G - 32G,默认开启内存压缩 ClassPointers Oops
- 32G,压缩无效,使用64位
内存并不是越大越好(^-^)
IdentityHashCode的问题
回答白马非马的问题:
当一个对象计算过identityHashCode之后,不能进入偏向锁状态
https://cloud.tencent.com/developer/article/1480590
https://cloud.tencent.com/developer/article/1484167
https://cloud.tencent.com/developer/article/1485795
https://cloud.tencent.com/developer/article/1482500
对象定位
•https://blog.csdn.net/clover_lily/article/details/80095580
- 句柄池
- 直接指针